| Daten analysieren | Anwendungen |
| Corpus Workbench | CQPweb recherchieren (UZH) |
 CQPweb: Recherche im Text+Berg-Korpus
CQPweb: Recherche im Text+Berg-Korpus
CQPweb ist das grafische Fenster auf die Corpus Workbench, einer mächtigen Korpusanalyse-Plattform. Die in der CWB und in CQPweb verwendete Abfragesprache heisst "CQP" und ist sehr flexibel. Wenn die Korpusdaten annotiert sind, können diese Informationen mit CQP abgefragt werden.
Überblick über diese Seite
- Das Text+Berg-Korpus
- Erste Schritte
- Verteilung der Flexionsformen (Frequency Breakdown)
- Verteilung der Treffer über das Korpus (Distribution)
- Berechnung von Kollokationen (Collocations)
- Weitere Analysefunktionen
- Mit Teilkorpora arbeiten (Restricted Query)
- Berechnen des typischen Vokabulars (Keywords)
- Suche nach Wortarten, Lemmata etc.
Screencast zur Bedienung von CQPweb
Am Beispiel des Spiegel/Zeit-Korpus zeige ich die wichtigsten Funktionen von CQPweb.
Das Text+Berg-Korpus
Wir wollen die Abfragesprache CQP und die Funktionen von CQPweb am Beispiel des Text+Berg-Korpus zeigen. Das Korpus umfasst knapp 200 Bände des Jahrbuchs des Schweizer Alpenclubs und der Nachfolgepublikation "Alpen" von 1864 bis heute, was über 35 Mio. Wortformen sind. Es gibt jedoch auch andere Korpora, die über CQP und CQPweb abfragbar sind.
Erste Schritte
Wichtig: Um das Text+Berg-Korpus nutzen zu können, ist eine kostenlose Anmeldung notwendig.
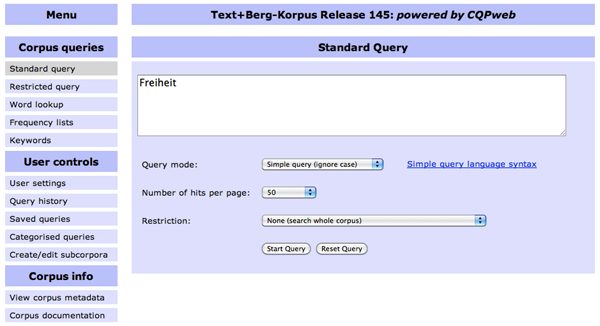
- Der aktuelle Zugang zum Korpus ist immer auf der Text+Berg-Seite ersichtlich.
- Der Bildschirm gliedert sich in verschiedene Menüs links und das Suchfenster auf der rechten Seite (siehe Abbildung oben).
- Abhängig davon, was unterhalb des Suchfensters als "Query Mode" ausgewählt ist, gestaltet sich die Suchanfrage. Bitte wähle "Simple Query (ignore case)" für den Start.
- Gib nun ein beliebiges Suchwort ein, z.B.:
Klicke dann auf "Start Query".Frieden - Nun wird eine KWiC-Liste mit Belegen ausgegeben.
- Ein Klick (oder darüberfahren) auf den Dateinamen ganz links gibt für jede Zeile die Metadaten aus.
- Fährt man mit der Maus über das Suchwort in der KWiC-Zeile, wird der unmittelbare Kontext mit den Wortarten-Annotationen ausgegeben.
- Ein Klick auf der Suchwort zeigt den weiteren Kontext an.

Ganz oben auf der KWiC-Seite werden Frequenzinformationen angegeben. In der Zeile darunter kann über "Line View" eine Satz-Darstellung erzeugt und über "Show in random order" können die Belege zufällig sortiert werden. Zudem verbergen sich hinter dem Menü "New query" einige interessante Funktionen, die im Folgenden beschrieben werden.
Wir haben nun mit der Eingabe "Frieden" nach genau dieser Wortform gesucht und finden deshalb keine flektierten Formen davon. Da das Korpus jedoch mit Lemma-Informationen annotiert ist, können wir nach dem Lemma (der Grundform) "Frieden" suchen. Das geht folgendermassen:
- Gehe zurück zur Suchmaske indem du im Menü rechts oben "New query" einstellst und auf "Go!" klickst.
- Nun benutzen wir die Abfragesprache "CQP" und stellen deshalb unterhalb des Suchfensters als "Query syntax" die Option "CQP Syntax" ein.
- Der Suchbefehl für eine Lemmasuche lautet:
[lemma="Frieden"] - Der Klick auf "Start Query" führt die Suche aus. In den KWiCs ist nun sichtbar, dass nach allen Flexionsformen von "Frieden" gesucht wurde.
Ausführlichere Informationen zur CQP-Syntax findet sich auf der nächsten Seite und natürlich in der offiziellen Dokumentation.
Verteilung der Flexionsformen (Frequency Breakdown)
Wähle im Menü "New query" oberhalb der KWiC-Zeilen rechts den Befehl "Frequency Breakdown". Nun ist ersichtlich, welche Wortformen des Suchbegriffs im Korpus mit welcher Frequenz vorkommen. Wenn nicht nach dem Lemma, sondern nach einer konkreten Wortform gesucht wird, dann fallen natürlich alle Treffer auf die eine Wortform. Bei der Suche nach
| [lemma="Frieden"] |
| No. | Search result | No. of occurrences | Percent |
| 1 | Frieden | 328 | 81.39% |
| 2 | Friedens | 75 | 18.61% |
Es ist zudem Möglich, auch die Wortarten-Informationen in die Verteilung einzubeziehen: Dafür muss im Menü oben, das auf "New query" voreingestellt ist, die entsprechende Auswahl getroffen werden. So kann man z.B. ersehen, auf welche Wortarten das Lemma "Frieden" entfällt – das ist bei diesem Beispiel trivial: Es handelt sich immer um Nomen.
Verteilung der Treffer über das Korpus (Distribution)
Wähle im Menü "New query" oberhalb der KWiC-Zeilen rechts den Befehl "Distribution". Nun kann die Verteilung der Treffer über verschiedene Kategorien dargestellt werden:
- Wähle im Menü "Categories" statt "General Information" eine sinnvollere Kategorie. Es bieten sich "text_year" (Publikationsjahr), "text_decade" (Publikationsdekade) oder "text_lang" (Sprache des Textes) an.
- Es lässt sich auch eine Kreuztabelle ausgeben, wenn als "Category for Crosstabs" eine weitere Kategorie ausgewählt wird.
- Mit dem Klick auf "Show distribution" wird eine Tabelle mit den Frequenzwerten pro Kategorieneinheit, also z.B. pro Jahr erstellt. Dabei werden neben den absoluten Trefferzahlen ("Hits in category") einerseits ein Dispersionswert (Anzahl Texte mit mindestens einem Treffer) und Frequenzwerte (Anzahl Treffer pro Million Wörter) angezeigt.
- Wenn man im Menü "Show as" statt "Distribution table" "Bar chart" wählt, werden die Frequenzwerte als Balkengrafik ausgegeben.
Über diese Funktion lassen sich Veränderungen der Frequenzen eines Ausdrucks über die Zeit gut darstellen. Der folgende Bildausschnitt zeigt die Frequenzen für
| [lemma="Führer"] |

Achtung: Bei Darstellungen dieser Art ist zu beachten, dass das Korpus nicht nur aus deutschsprachigen Texten besteht, aber nicht in jedem Jahrgang die Anteile von nicht-deutschen Texten gleich ist. Deshalb ist es sinnvoll, ein Teilkorpus, nur aus deutschsprachigen Texten bestehend, zu bilden. Wie das funktioniert, wird weiter unten erklärt.
Berechnung von Kollokationen (Collocations)
In CQPweb ist es möglich, sich die Kollokationen (manchmal auch: "Kookkurrenzen" genannt) zum Suchbegriff zu berechnen. Verwende dazu im Menü "New query" den Befehl "Collocations".
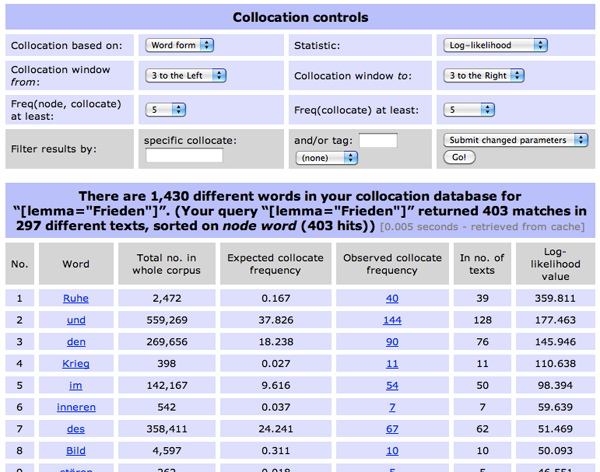
- Als erstes kann man die Einstellungen für die Art der Berechnung vornehmen. Es ist sinnvoll, "Lemma" (die Grundformen) und "POS" (Wortarten) in die Berechnung einzubeziehen. Zudem kann das Fenster der Anzahl Wörter links und rechts vom Suchbegriff ("Maximum Window Span") bestimmt werden.
- Die Tabelle (vgl. Abbildung oben) gibt nun die signifikantesten Kollokatoren zum Suchbegriff aus. Es werden die absoluten und relativen beobachteten und (aufgrund der statistischen Verteilung) erwarteten Frequenzen sowie der statistische Signifikanzwert (Standard: Log-likelihood) angegeben.
- Man kann nun über die diversen Einstellmöglichkeiten oben die Liste filtern:
- Über "Collocation based on" kann man anstelle der Wortform die Kollokatoren auf der Basis der Grundformen (Lemmata) oder Wortarten (POS) ausgeben lassen.
- Man kann über "Collocation window from/to" das Fenster einschränken und nur Kollokatoren in einem bestimmten Bereich links und rechts des Suchbegriffs ausgeben lassen.
- Über "Freq(node, collocate) at least" kann man die Mindestfrequenz, mit der eine Kollokation oder ein Kollokator – "Freq(collocate) at least" – auftreten muss, bestimmen.
- Man kann in "Statistics" das statistische Mass für die Berechnung bestimmen.
- Und es ist möglich, die Liste nach bestimmten Wortformen, Lemmata oder Wortarten zu filtern ("Filter results by").
Weitere Analysefunktionen
Hinter dem Menü "New query", das oberhalb einer KWiC-Liste angezeigt wird, verbergen sich noch weitere interessante Funktionen. In Kürze:
- Thin: Aus der Belegmenge kann eine Zufallsauswahl für die genauere Analyse gezogen werden.
- Sort: Die Belege können nach verschiedenen Kriterien sortiert werden.
- Download: Die Belege können heruntergeladen werden.
- Categorise: Die Belege können nach eigenen Kriterien kategorisiert und diese Kategorisierung gespeichert werden.
- Save current set of hits: Die Suche kann in CQPweb gespeichert werden, damit man sie später schnell wieder ausführen kann.
Mit Teilkorpora arbeiten (Restricted Query)
Wahrscheinlich möchte man nicht immer mit dem gesamten Korpus arbeiten. Das Text+Berg-Korpus ist z.B. mehrsprachig und so möchte man die Suche vielleicht auf eine Sprache einschränken. Solche Einschränkungen sind über "Restricted Query" möglich; der Menüpunkt findet sich in der linken Menüspalte.
Auch da kann man im Suchfenster den Suchausdruck mit den gleichen Mitteln formulieren wie bei der normalen Suche. Zusätzlich kann man aber die Suche auf Texte mit bestimmten Metadaten beschränken. Die Listen unten führen alle Metadaten-Kategorien auf, die verwendet werden können, um die Suche einzuschränken. So kann man z.B. in der Liste text_decade die Suche auf bestimmte Jahrzehnte oder in text_lang auf bestimmte Sprachen einschränken.
- text_lang: Sprache des Satzes
- ch-de: Schweizerdeutsch
- de: Deutsch
- en: Englisch
- fr: Französisch
- it: Italienisch
- ro: Romanisch
- text_year: Publikationsjahr des Bandes
- text_decade: Publikationsdekade des Bandes
Man kann nun beliebige Kategorien ankreuzen und damit nur darin suchen.
Berechnen des typischen Vokabulars (Keywords)
Links im Menü von CQPweb finden Sie unter "Corpus queries" den Bereich "Keywords". Damit lässt sich das für ein bestimmtes Korpus im Vergleich zu einem anderen Korpus typische Vokabular berechnen. Dafür müssen für die Korpora, die verglichen werden sollen, vorberechnete Frequenzlisten zur Verfügung stehen. Für das Korpus, mit dem Sie arbeiten, ist dies bereits der Fall. Ggf. liegen zudem von anderen Korpora, die auf dem Server verfügbar sind, Frequenzlisten vor.
- Sie können nun zwei Frequenzlisten auswählen: Unter "Select frequency list 1" lassen Sie die Frequenzliste des aktuellen Korpus ausgewählt. Unter "Select frequency list 2" wählen Sie die Liste eines Vergleichskorpus.
- Nun können Sie noch die Einheit, die verglichen werden soll ("Compare") auswählen: Voreingestellt ist "Word forms", es werden also Wortformen verglichen. Alternativ können Sie dort "Lemma" auswählen, um Grundformen zu vergleichen oder "POS", um die Verteilung der Wortarten zu vergleichen.
- Es gibt nun noch die Möglichkeit, Optionen zu den Mindestfrequenzen und der gewünschten Statistik auszuwählen – belassen Sie die Einstellungen erstmal wie sie sind.
- Nun klicken Sie "calculate keywords!".
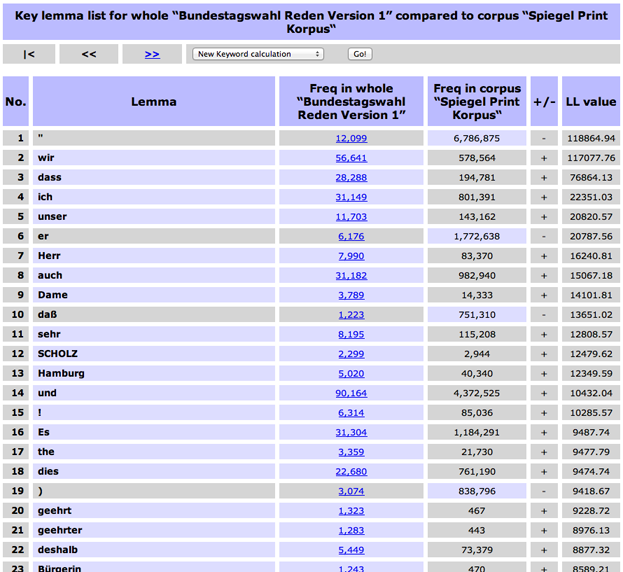
In der Eregbnisliste werden nun, geordnet nach statistischer Signifikanz, die Wörter angezeigt, die für das Untersuchungskorpus und das Referenzkorpus typisch sind. Blau hinterlegt und mit + verstehen sind die typischen Bundestagswahl-Wörter, grau hinterlegt und mit - versehen, das Vokabular des Referenzkorpus. Zusätzlich sind die absoluten Frequenzen jedes Wortes in den beiden Korpora und der statistische Signifikanzwert angegeben.
Um nun aber das Vokabular von zwei Teilkorpora innerhalb Ihres Untersuchungskorpus zu vergleichen, erstellen Sie erst zwei entsprechende Teilkorpora über den Menübefehl "User controls" -> "Create/edit subcorpora". Danach können Sie über die Keywords-Funktion die beiden Frequenzlisten miteinander vergleichen.
Suche nach Wortarten, Lemmata etc.
Interessant wird die Corpus Workbench und CQPweb natürlich besonders dann, wenn intelligentere Suchmöglichkeiten eingesetzt werden. Im nächsten Kapitel werden deshalb die wichtigsten Regeln der Abfragesprache CQP erklärt.
| Corpus Workbench | CQPweb recherchieren (UZH) |
| Daten analysieren | Anwendungen |
Diese elektronische Ressource soll wie folgt zitiert werden: Bubenhofer, Noah (2006-2025): Einführung in die Korpuslinguistik: Praktische Grundlagen und Werkzeuge. Elektronische Ressource: http://www.bubenhofer.com/korpuslinguistik/.