Monographien / Monographs
 Bubenhofer, Noah (2020): Visuelle Linguistik. Zur Genese, Funktion und Kategorisierung von Diagrammen in der Sprachwissenschaft. Linguistik – Impulse & Tendenzen, 90. Habilitationsschrift, angenommen von der Philosophischen Fakultät der Universität Zürich. De Gruyter, Berlin, DOI: 10.1515/9783110698732.
Bubenhofer, Noah (2020): Visuelle Linguistik. Zur Genese, Funktion und Kategorisierung von Diagrammen in der Sprachwissenschaft. Linguistik – Impulse & Tendenzen, 90. Habilitationsschrift, angenommen von der Philosophischen Fakultät der Universität Zürich. De Gruyter, Berlin, DOI: 10.1515/9783110698732.
Download PDF, BibTeX
Abstract
Grafiken, Diagramme, Schemata nehmen in der Linguistik wichtige Funktionen ein: Sie visualisieren Analyseergebnisse, verdeutlichen komplexe theoretische Konzepte oder ermöglichen überhaupt erst die Analyse von Daten. Es handelt sich dabei um Achsendiagramme, Netze, Listen, Karten und viele weitere Formen. Doch wie beeinflussen sie die Entstehung von wissenschaftlichen Tatsachen? In welche Handlungen sind sie eingebunden und welche Effekte haben sie auf sprachliche Daten? Wie ermöglichen Sie Transformationen von Daten, um neue Erkenntnisse zu gewinnen? Das Buch untersucht diagrammatische Praktiken in der Sprachwissenschaft sowohl aus historischer als auch technischer Sicht und zeigt die Einbettung dieser Praktiken in Diagrammkulturen und „Coding Cultures“. Die Vielfalt der Diagramme wird auf fünf diagrammatische Grundfiguren zurückgeführt, deren spezifischen Funktionen und Effekte analysiert werden. Semiotisch und wissenschaftstheoretisch unterfüttert wird sodann eine Methodologie der Visuellen Linguistik entwickelt.
Graphics, diagrams, schemata take on important functions in linguistics: they visualize analysis results, clarify complex theoretical concepts, or enable the analysis of data in the first place. They are axis diagrams, networks, lists, maps, and many other forms. But how do they influence the emergence of scientific facts? What actions are they involved in and what effects do they have on linguistic data? How do they enable transformations of data to yield new insights? This book examines diagrammatic practices in linguistics from both historical and technical perspectives, and shows how these practices are embedded in diagramming cultures and "coding cultures". The diversity of diagrams is traced back to five basic diagrammatic figures, whose specific functions and effects are analyzed. Underpinned by semiotics and scientific theory, a methodology of visual linguistics is then developed.
Les graphiques, les diagrammes, les schémas ont des fonctions importantes en linguistique : ils permettent de visualiser les résultats d'analyse, de clarifier des concepts théoriques complexes ou de permettre l'analyse des données en premier lieu. Il s'agit de diagrammes d'axes, de réseaux, de listes, de cartes et de bien d'autres formes. Mais comment influencent-ils l'émergence des faits scientifiques ? Quelles sont leurs actions et quels effets ont-ils sur les données linguistiques ? Comment permettent-ils de transformer les données afin d'obtenir de nouvelles informations ? L'ouvrage examine les pratiques diagrammatiques en linguistique d'un point de vue historique et technique et montre comment ces pratiques sont ancrées dans les cultures de diagramme et les "cultures de codage" ("coding cultures"). La diversité des diagrammes est retracée à partir de cinq figures diagrammatiques de base, dont les fonctions et les effets spécifiques sont analysés. Sur la base de fondements théoriques sémiotiques et scientifiques, une méthodologie de linguistique visuelle est ensuite développée.
 Bubenhofer, Noah/Konopka, Marek/Schneider, Roman (2014): Präliminarien einer Korpusgrammatik. Korpuslinguistik und interdisziplinäre Perspektiven auf Sprache (CLIP). Tübingen: Narr. Unter Mitarbeit von Caren Brinckmann, Katrin Hein und Bruno Strecker. BibTeX
Bubenhofer, Noah/Konopka, Marek/Schneider, Roman (2014): Präliminarien einer Korpusgrammatik. Korpuslinguistik und interdisziplinäre Perspektiven auf Sprache (CLIP). Tübingen: Narr. Unter Mitarbeit von Caren Brinckmann, Katrin Hein und Bruno Strecker. BibTeX
 Bubenhofer, Noah: Sprachgebrauchsmuster. Korpuslinguistik als Methode der Diskurs- und Kulturanalyse. (Sprache und Wissen 4), Berlin/New York, de Gruyter, 2009. DOI: 10.1515/9783110215854
Bubenhofer, Noah: Sprachgebrauchsmuster. Korpuslinguistik als Methode der Diskurs- und Kulturanalyse. (Sprache und Wissen 4), Berlin/New York, de Gruyter, 2009. DOI: 10.1515/9783110215854
Download PDF, BibTeX
- Rezension von Maik Walter in: Germanistik. Internationales Referatenorgan mit bibliographischen Hinweisen. Jg. 50. Heft 1/2, 27, 2009
- Rezension von Sibylle Reichel in: Linguistik online 42, 2/2010
- Rezension von Constanze Spieß in: Zeitschrift für Rezensionen zur germanistischen Sprachwissenschaft (Band 3, Heft 2, 2011, S. 195-200)
- Rezension von Sven Staffeldt in: Studia Germanistica 11, 2012. S. 145-149.
Aus der Rezension: "Wenn man es nicht weiß, merkt man es nicht:
'Sprachgebrauchsmuster' von Noah Bubenhofer hat
wenig Dissertationshaftes. Nicht, dass es unbedingt
schlimm für ein Buch wäre, erkennbar eine Dissertation
zu sein. Aber diese Dissertation ist eher ein großer Wurf als eine kleine Qualifikationsschrift." (Staffeldt: 145)
 Bubenhofer, Noah: Einführung in die Korpuslinguistik: Praktische Grundlagen und Werkzeuge. Elektronische Ressource, Zürich, 2006-2017. http://www.bubenhofer.com/korpuslinguistik Online
Bubenhofer, Noah: Einführung in die Korpuslinguistik: Praktische Grundlagen und Werkzeuge. Elektronische Ressource, Zürich, 2006-2017. http://www.bubenhofer.com/korpuslinguistik Online
 Stocker, Christa/Macher, Daniela/Studler, Rebekka/Bubenhofer, Noah/Crvelin, Daniel/Liniger, Reto/Volk, Martin: Studien-CD Linguistik. Multimediale Einführungen und interaktive Übungen zur germanistischen Sprachwissenschaft. Tübingen, Max Niemeyer, 2004. [CD-ROM]
Stocker, Christa/Macher, Daniela/Studler, Rebekka/Bubenhofer, Noah/Crvelin, Daniel/Liniger, Reto/Volk, Martin: Studien-CD Linguistik. Multimediale Einführungen und interaktive Übungen zur germanistischen Sprachwissenschaft. Tübingen, Max Niemeyer, 2004. [CD-ROM]
Reihenherausgeberschaften / Series Editor
 Reihe Germanistische Linguistik (RGL), de Gruyter, zusammen mit Britt-Marie Schuster, Online Call for Book Proposals
Reihe Germanistische Linguistik (RGL), de Gruyter, zusammen mit Britt-Marie Schuster, Online Call for Book Proposals
 Zeitschrift für germanistische Linguistik (ZGL), de Gruyter, zusammen mit Vilmos Ágel, Helmuth Feilke, Wolfgang Imo, Anke Lüdeling, Doris Tophinke Online
Zeitschrift für germanistische Linguistik (ZGL), de Gruyter, zusammen mit Vilmos Ágel, Helmuth Feilke, Wolfgang Imo, Anke Lüdeling, Doris Tophinke Online
Herausgeberschaft / Edited Volumes
 Bubenhofer, Noah/Knuchel, Daniel/Schüller, Larissa (Hrsg.) (2021): Kulturlinguistik in der Schweiz. In: Germanistik in der Schweiz, Sonderheft „Kulturlinguistik“ 18. Mit Beiträgen von: Noah Bubenhofer, Nadia Brügger, Karina Frick, Christoph Hottiger, Daniel Knuchel, Martin Luginbühl, Salomé Meier, Ina Pick, Juliane Schröter, Larissa Schüller, Livia Sutter, Vera Thomann, Thomas Traupmann, Tobias von Waldkirch. DOI:10.24894/GiS.2021.18.1 Online
Bubenhofer, Noah/Knuchel, Daniel/Schüller, Larissa (Hrsg.) (2021): Kulturlinguistik in der Schweiz. In: Germanistik in der Schweiz, Sonderheft „Kulturlinguistik“ 18. Mit Beiträgen von: Noah Bubenhofer, Nadia Brügger, Karina Frick, Christoph Hottiger, Daniel Knuchel, Martin Luginbühl, Salomé Meier, Ina Pick, Juliane Schröter, Larissa Schüller, Livia Sutter, Vera Thomann, Thomas Traupmann, Tobias von Waldkirch. DOI:10.24894/GiS.2021.18.1 Online
 Bubenhofer, Noah/Kupietz, Marc (Hrsg.) (2018): Visualisierung sprachlicher Daten: Visual Linguistics – Praxis – Tools. Heidelberg: Heidelberg University Publishing. DOI: 10.17885/heiup.345.474. Online PDF/HTML
Bubenhofer, Noah/Kupietz, Marc (Hrsg.) (2018): Visualisierung sprachlicher Daten: Visual Linguistics – Praxis – Tools. Heidelberg: Heidelberg University Publishing. DOI: 10.17885/heiup.345.474. Online PDF/HTML
Bubenhofer, Noah/Scharloth, Joachim (Hrsg.) (2015): Maschinelle Textanalyse, Themenheft der Zeitschrift für Germanistische Linguistik. 43/1.
 Ptashnyk, Stefaniya/Hallsteinsdóttir, Erla/Bubenhofer, Noah (Hrsg.): "Korpora, Web und Datenbanken. Computergestützte Methoden in der modernen
Phraseologie und Lexikographie/Corpora, Web and Databases. Computer-Based Methods in Modern Phraseology
and Lexicography." Phraseologie & Parömiologie, Hohengehren, Schneider Verlag, 2010.
Ptashnyk, Stefaniya/Hallsteinsdóttir, Erla/Bubenhofer, Noah (Hrsg.): "Korpora, Web und Datenbanken. Computergestützte Methoden in der modernen
Phraseologie und Lexikographie/Corpora, Web and Databases. Computer-Based Methods in Modern Phraseology
and Lexicography." Phraseologie & Parömiologie, Hohengehren, Schneider Verlag, 2010.
Download über ZORA-Datenbank
Download PDF
Inhaltsverzeichnis
Rezension von Leonard Pon (Jezikoslovlje, Vol.11 No.2 Prosinac 2010)
Aufsätze / Original Articles
Im Druck/eingereicht
 Bubenhofer, Noah (im Druck): „Wissenschaftliches Schreiben mit KI: Schreibmaschine oder Programmierung?“, in: Weder, Mirjam und Noah Bubenhofer (Hrsg.): Schreiben mit KI in der Literatur und im Alltag, Bielefeld: Transcript. Preprint (PDF)
Bubenhofer, Noah (im Druck): „Wissenschaftliches Schreiben mit KI: Schreibmaschine oder Programmierung?“, in: Weder, Mirjam und Noah Bubenhofer (Hrsg.): Schreiben mit KI in der Literatur und im Alltag, Bielefeld: Transcript. Preprint (PDF)
Bubenhofer, Noah (in print): „Qualitative and quantitative text analysis“, in: Roelcke, Thorsten, Ruth Breeze und Jan Engberg (Hrsg.): Specialized Communication: an International Handbook, Handbücher zur Sprach- und Kommunikationswissenschaft / Handbooks of Linguistics and Communication Science [HSK] 47/1, Boston: De Gruyter Mouton.
Kellenberger, Maaike / Bubenhofer, Noah (eingereicht): „Offenlegung gegenderter Identitäten in der Populärkultur: Kollokationsprofile lesbar machen“, in: Kabatnik, Susanne u. a. (Hrsg.): Genderpragmatik, Studien zur Pragmatik, Tübingen: Narr.
Bubenhofer, Noah (eingereicht): „Vektorisierte Praktiken: Ein linguistisches Verständnis von Large Language Models“, Zeitschrift Leseräume, Sonderheft „Forschungsperspektiven zu KI und Schreiben“.
Preprint (PDF)
Bubenhofer, Noah (im Druck): „Performanz: Drei Thesen zur textgenerierenden KI“, Aue Stiftung.
Bubenhofer, Noah und Joachim Scharloth (im Druck): „Textanalyse im Data-driven Turn: Von den Anfängen bis zum wahrscheinlichen Ende der datengeleiteten Korpuslinguistik“, OBST. Osnabrücker Beiträge zur Sprachtheorie.
Elliker, Florian und Noah Bubenhofer (im Druck): „Zwischen quantitativ und qualitativ, Oberfläche und Tiefe: Methodische Experimente am Beispiel von Einbürgerungsdiskursen in der Schweiz“, Zeitschrift für Diskursforschung.
 Bubenhofer, Noah (2024): Textgenerierende künstliche Intelligenz: Revolution oder Evolution? In: dt. Fachpublikation für zeitgemässen Deutschunterricht. 4 , S. 87–111.
Preprint Online BibTeX
Bubenhofer, Noah (2024): Textgenerierende künstliche Intelligenz: Revolution oder Evolution? In: dt. Fachpublikation für zeitgemässen Deutschunterricht. 4 , S. 87–111.
Preprint Online BibTeX
 Bubenhofer, Noah (2024): „Grammatik“, Zeitschrift für Medienwissenschaft 1/30, S. 53–55.
Online
BibTeX
Bubenhofer, Noah (2024): „Grammatik“, Zeitschrift für Medienwissenschaft 1/30, S. 53–55.
Online
BibTeX
 Bubenhofer, Noah: Die Lektüre von Texten und Daten: Data Philology statt Data Science. In: Zeitschrift für Literaturwissenschaft und Linguistik (2024).
Online
BibTeX
Abstract
Bubenhofer, Noah: Die Lektüre von Texten und Daten: Data Philology statt Data Science. In: Zeitschrift für Literaturwissenschaft und Linguistik (2024).
Online
BibTeX
Abstract
In meinem Artikel hinterfrage ich die traditionelle Trennung zwischen qualitativer und quantitativer Textanalyse und plädiere für eine integrierte Herangehensweise, die ich als Data Philology bezeichne. Ich argumentiere, dass das Lesen von Texten und Daten in ihrer Komplexität keinen grundlegenden Unterschied aufweist, insbesondere wenn man die Rolle diagrammatischer Transformationen, Algorithmisierung und maschineller Prozesse berücksichtigt.
Im Zentrum meiner Ausführungen steht die Korpuslinguistik, die durch statistische Methoden und digitale Codierung großangelegte Textanalysen ermöglicht. Diese Ansätze überschreiten die herkömmlichen Grenzen zwischen »close« und »distant reading«. Ich beleuchte, wie Computer als aktive Mitwirkende in Schreib- und Lesepraktiken fungieren und wie digitale wie auch analoge Methoden oft diagrammatische Operationen involvieren, die in komplexe Interpretationsprozesse eingebettet sind.
Ich vertrete die Ansicht, dass die Philologie von der Integration datenwissenschaftlicher Methoden profitieren kann, indem sie diese für philologische Forschungsinteressen nutzt. Ziel ist es, einen naiven Datenpositivismus zu vermeiden und statistische Modelle für interpretative Zwecke zugänglich zu machen.
Mein Artikel fordert dazu auf, traditionelle Sichtweisen zu überdenken und sich für eine Data Philology zu öffnen, die die neuesten Methoden der Datenanalyse kritisch integriert und für eine breitere Vielfalt an Textanalysen nutzt.
(Das Abstract wurde maschinell mit ChatGPT (GPT 4.0 vom 3. Januar 2024) auf Basis des Manuskripts erstellt und nur minimal korrigiert.)
In my article, I question the traditional separation between qualitative and quantitative text analysis and argue for an integrated approach, which I call data philology. I argue that reading texts and data are not fundamentally different in their complexity, especially when considering the role of diagrammatic transformations, algorithmization and machine processes.
At the center of my argument is corpus linguistics, which enables large-scale text analysis through statistical methods and digital coding. These approaches transcend the conventional boundaries between »close« and »distant reading«. I highlight how computers function as active participants in writing and reading practices and how digital as well as analog methods often involve diagrammatic operations embedded in complex interpretive processes.
I argue that philology can benefit from the integration of data science methods by utilizing them for philological research interests. The aim is to avoid naïve data positivism and to make statistical models accessible for interpretative purposes.
My article calls for rethinking traditional perspectives and opening up to a data philology that critically integrates and utilizes the latest methods of data analysis for a wider variety of textual analyses.
(The title and abstract was automatically translated from German using DeepL (version 23.11).)
Bender, Michael/Bubenhofer, Noah/Janich, Nina: Die öffentliche Aushandlung von Expertise: Wissenschaftsblogs als Ort eristischer Verständigung? Exploratorischer Einstieg in ein Forschungsprojekt. In: Zeitschrift für germanistische Linguistik Bd. 52 (2024), Nr. 1, S. 183–211. Online
BibTeX
Graën, Johannes; Schaber, Jonathan; McDonald, Daniel; Mustač, Igor; Rajović, Nikolina; Schneider, Gerold; Zehr, Jeremy; Bubenhofer, Noah: The LiRI Corpus Platform. In: CLARIN 2023 Proceedings. Leuven, 2024.
Online
BibTeX
 Knuchel, Daniel & Noah Bubenhofer (2023): Machine Learning und Korpuspragmatik. Word Embeddings als Beispiel für einen kreativen Umgang mit NLP-Tools. In: Simon Meier-Vieracker, Lars Bülow, Konstanze Marx & Robert Mroczynski (eds.), Digitale Pragmatik (Digitale Linguistik), vol. 1, 213–235. Berlin, Heidelberg: Springer Berlin Heidelberg. https://doi.org/10.1007/978-3-662-65373-9_10. Online BibTeX
Knuchel, Daniel & Noah Bubenhofer (2023): Machine Learning und Korpuspragmatik. Word Embeddings als Beispiel für einen kreativen Umgang mit NLP-Tools. In: Simon Meier-Vieracker, Lars Bülow, Konstanze Marx & Robert Mroczynski (eds.), Digitale Pragmatik (Digitale Linguistik), vol. 1, 213–235. Berlin, Heidelberg: Springer Berlin Heidelberg. https://doi.org/10.1007/978-3-662-65373-9_10. Online BibTeX
 Bubenhofer, Noah (2023): „Corpus Linguistics in Discourse Analysis: No Bodies and no Practices?“, Zeitschrift für Diskursforschung 2, S. 195–204. DOI: 10.3262/ZFD2202195.
Online
BibTeX
Abstract
Bubenhofer, Noah (2023): „Corpus Linguistics in Discourse Analysis: No Bodies and no Practices?“, Zeitschrift für Diskursforschung 2, S. 195–204. DOI: 10.3262/ZFD2202195.
Online
BibTeX
Abstract
In der Korpuslinguistik werden große Textmengen mit quantitativen Methoden analysiert, auch für diskursanalytische Zwecke. Diese Methoden sind jedoch auf den ersten Blick begrenzt, weil ihre Analysen auf die sprachliche Oberfläche beschränkt sind und der Komplexität des Diskurses und der Kultur nicht gerecht werden. Dies wird insbesondere aus der Perspektive der Praxistheorie deutlich, die Körper, Raum und Zeit als konstitutive Faktoren von Handlungen betrachtet. Ich argumentiere, dass korpuspragmatische Methoden das Konzept der Praktiken sehr gut in die Analyse integrieren können und zeige dies an einem Beispiel, das Methoden der distributiven Semantik verwendet.
In corpus linguistics, large amounts of text are analysed using quantitative methods, also for discourse-analytical purposes. However, these methods are limited at first glance because their analyses are restricted to the linguistic surface and do not do justice to the complexity of discourse, and culture. This becomes particularly clear from the perspective of practice theory, which sees body, space and time as constitutive factors of actions. I argue that corpus pragmatic methods can very well integrate the concept of practices into the analysis and show this with an example that uses methods of distributive semantics.
Dans la linguistique de corpus, de grandes quantités de textes sont analysées à l'aide de méthodes quantitatives, également à des fins d'analyse du discours. Cependant, ces méthodes sont limitées à première vue parce que leurs analyses se limitent à la surface linguistique et ne rendent pas justice à la complexité du discours et de la culture. Cela devient particulièrement clair dans la perspective de la théorie de la pratique, qui considère le corps, l'espace et le temps comme des facteurs constitutifs des actions. Je soutiens que les méthodes pragmatiques de corpus peuvent très bien intégrer le concept de pratiques dans l'analyse et je le montre à l'aide d'un exemple qui utilise les méthodes de la sémantique distributive.
 Bubenhofer, Noah; Schröter, Juliane (2022): Partizipation und Egalität – Diskurse um soziale Teilhabe und Solidarität sowie Diversität und Gleichberechtigung seit 1990. In: Aptum, Zeitschrift für Sprachkritik und Sprachkultur. 18 (3), DOI: 10.46771/9783967692877_2. Online
BibTeX
Abstract
Bubenhofer, Noah; Schröter, Juliane (2022): Partizipation und Egalität – Diskurse um soziale Teilhabe und Solidarität sowie Diversität und Gleichberechtigung seit 1990. In: Aptum, Zeitschrift für Sprachkritik und Sprachkultur. 18 (3), DOI: 10.46771/9783967692877_2. Online
BibTeX
Abstract
Die Debatten um Partizipation und Egalität, die in den letzten Jahrzehnten in der deutschen und Schweizer Öffentlichkeit stattgefunden haben, basieren oft auf denselben Werten und Prämissen. Sie gewinnen ihre Explosivität aus der subkutanen Veränderung dieser Werte und Prämissen. Dies sind die Grundhypothesen, die dem Teilprojekt „Partizipation und Egalität“ der Forschungsgruppe „Kontroverse Diskurse“ unterliegen. Weil wir ein gemeinsames Werte- und Prämissenfundament der Diskurse um Partizipation und Egalität vermuten, wollen wir diese Diskurse in einem gemeinsamen Teilprojekt untersuchen. In diesem Beitrag präsentieren wir erste analytische Probebohrungen im Teilprojekt „Partizipation und Egalität“. Das Teilprojekt widmet sich der Erforschung der entsprechenden öffentlichen Presse-Diskurse in Deutschland und der Deutschschweiz seit ca. 1990, und zwar schwerpunktmäßig mit korpuspragmatischen Methoden in zwei Teilphasen: In der ersten Teilphase stehen die Diskurse um Partizipation, soziale Teilhabe und Solidarität im Zentrum, in der zweiten die Diskurse um Egalität, Diversität und Gleichberechtigung. In den Texten, die diesen Diskursen zugerechnet werden können, müssen die Ausdrücke Partizipation, Teilhabe, Solidarität bzw. Egalität, Diversität, Gleichberechtigung allerdings nicht vorkommen. Es geht uns vielmehr um Texte und Diskurse, die inhaltlich die Themen ‚Partizipation, soziale Teilhabe, Solidarität, soziale Sicherungssysteme im Kontext von Lebensrisiken‘ einerseits und ,Egalität, Gleichberechtigung, Diversität, Gleichstellung im Kontext von Diskriminierung‘ andererseits betreffen.
In diesem Beitrag stellen wir das Projekt vor und illustrieren anschließend die geplante Methodik anhand erster Analysen. Dabei kommen klassische und neuere Instrumente der Korpuspragmatik zum Einsatz, nämlich die Analyse von Kollokationen sowie die von Word Embeddings.
The debates about participation and egalitarianism that have taken place in the German and Swiss public spheres in recent decades are often based on the same values and premises. They gain their explosiveness from the subcutaneous change of these values and premises. These are the basic hypotheses underlying the subproject "Participation and Egalitarianism" of the research group "Controversial Discourses". Because we assume a common value and premise foundation of the discourses around participation and egalitarianism, we want to investigate these discourses in a joint subproject. In this paper, we present first analytical test drillings in the subproject "Participation and Egalitarianism". The subproject is devoted to the study of the corresponding public press discourses in Germany and the German-speaking part of Switzerland since ca. 1990, with a focus on corpus-pragmatic methods in two subphases: The first subphase focuses on discourses of participation, social involvement, and solidarity; the second on discourses of egalitarianism, diversity, and equality. In the texts that can be attributed to these discourses, however, the expressions participation, sharing, solidarity or equality, diversity, equity do not have to occur. Rather, we are concerned with texts and discourses which, in terms of content, relate to the themes of 'participation, social participation, solidarity, social security systems in the context of life risks' on the one hand, and 'equality, equity, diversity, equality in the context of discrimination' on the other.
In this paper we introduce the project and then illustrate the planned methodology by means of first analyses. Classical and newer instruments of corpus pragmatics are used, namely the analysis of collocations as well as that of word embeddings.
Les débats sur la participation et l'égalitarisme qui ont eu lieu dans l'opinion publique allemande et suisse au cours des dernières décennies sont souvent basés sur les mêmes valeurs et prémisses. Ils tirent leur explosivité de la modification sous-cutanée de ces valeurs et prémisses. Telles sont les hypothèses de base qui sous-tendent le sous-projet "Participation et égalitarisme" du groupe de recherche "Discours controversés". Comme nous supposons qu'il existe un socle commun de valeurs et de présupposés dans les discours sur la participation et l'égalitarisme, nous souhaitons étudier ces discours dans le cadre d'un sous-projet commun. Dans cet article, nous présentons les premiers essais analytiques du sous-projet "Participation et égalité". Le sous-projet se consacre à l'étude des discours de la presse publique en Allemagne et en Suisse alémanique depuis 1990 environ, en se concentrant sur des méthodes pragmatiques de corpus en deux phases : Dans la première phase, l'accent est mis sur les discours de la participation, de la participation sociale et de la solidarité, dans la deuxième phase sur les discours de l'égalitarisme, de la diversité et de l'égalité. Dans les textes qui relèvent de ces discours, les termes participation, partage, solidarité ou égalitarisme, diversité, égalité ne sont pas forcément présents. Nous nous intéressons plutôt aux textes et aux discours dont le contenu concerne les thèmes 'Participation, participation sociale, solidarité, systèmes de sécurité sociale dans le contexte des risques de la vie' d'une part et 'Egalité, équité, diversité, égalité dans le contexte de la discrimination' d'autre part.
Dans cet article, nous présentons le projet et illustrons ensuite la méthodologie prévue à l'aide des premières analyses. Nous utiliserons des outils classiques et plus récents de la pragmatique de corpus, à savoir l'analyse des collocations et celle des embeddings de mots.
 Bubenhofer, Noah (2022): Exploration par corpus linguistique d’espaces sémantiques en discours. Dans: Nouveaux Cahier d’Allemand 40 (Octobre), p. 107–128.
BibTeX
Abstract
Bubenhofer, Noah (2022): Exploration par corpus linguistique d’espaces sémantiques en discours. Dans: Nouveaux Cahier d’Allemand 40 (Octobre), p. 107–128.
BibTeX
Abstract
Les mots sont sémantisés de manière très différente selon les contextes dans les-quels ils sont utilisés. Cela dépend souvent du discours considéré, dans la me-sure où les différents acteurs y utilisent les mêmes expressions de façon dissem-blable. Les méthodes de linguistique de corpus permettent de mesurer systéma-tiquement et quantitativement ces différentes sémantisations. Pour ce faire, il est proposé d'utiliser des méthodes de sémantique distributive, le calcul de word embeddings. Cependant, pour que de tels calculs soient utilisables à des fins de linguistique du discours, il est important de combiner ces méthodes avec des analyses qualitatives. L'exemple du discours Corona en Suisse alémanique montre l'application d'une méthode basée sur les Word Embeddings.
 Krasselt, Julia/Robin, Dominik/Fadda, Marta/Geutjes, Anita/Bubenhofer, Noah/Suzanne Suggs, L./Dratva, Julia (2022): Tick-Talk: Parental online discourse about TBE vaccination. In: Vaccine, https://doi.org/10.1016/j.vaccine.2022.10.055.
Online
BibTeX
Abstract
Krasselt, Julia/Robin, Dominik/Fadda, Marta/Geutjes, Anita/Bubenhofer, Noah/Suzanne Suggs, L./Dratva, Julia (2022): Tick-Talk: Parental online discourse about TBE vaccination. In: Vaccine, https://doi.org/10.1016/j.vaccine.2022.10.055.
Online
BibTeX
Abstract
This study aimed to understand parental discourse about vaccination, and to provide guidance for communication that addresses the needs of parents. We analyzed parental discourse on child vaccination in general and tick-borne encephalitis (TBE) specifically in a Swiss parental online community. For this purpose, a data set containing 105k posts written by parents between 2007 and 2019 was analyzed using a combination of linguistic discourse analysis and qualitative content analysis. Results show that parents enter into a multidimensional decision-making process, characterized by elaborate practices of negotiation, consideration of vaccination recommendations as well as six distinct influencing thematic factors (vaccination safety, development and control, effectiveness, epidemiology, necessity, alternatives or additional prevention methods). The study shows a clear pattern of seasonality, with parents talking about TBE vaccination mostly triggered by events such as tick bites in spring and summer. From a public health perspective, the study emphasizes the need for sufficient, balanced, and tailored information about TBE vaccination. Online forums provide valuable information about what matters to parents and when, which can help public health authorities and practitioners provide information according to these concerns and enhance health literacy among parents.
 Sutter, Livia/Bubenhofer, Noah (2022): Zwischen Empirie und Hermeneutik. Korpuspragmatische Analyse zu „link“ und „rechts“. In: Brommer, S./Roth, K. S./Spitzmüller, J. (Hrsg.): Brückenschläge: Linguistik an den Schnittstellen. Tübingen: Gunter Narr Verlag, 2022. DOI: 10.24053/9783823395188.
Online
BibTeX
Sutter, Livia/Bubenhofer, Noah (2022): Zwischen Empirie und Hermeneutik. Korpuspragmatische Analyse zu „link“ und „rechts“. In: Brommer, S./Roth, K. S./Spitzmüller, J. (Hrsg.): Brückenschläge: Linguistik an den Schnittstellen. Tübingen: Gunter Narr Verlag, 2022. DOI: 10.24053/9783823395188.
Online
BibTeX
 Bubenhofer, Noah/Dreesen, Philipp (2022): Kollektivierungs- und Individualisierungseffekte. In: Diskurse – digital. De Gruyter. S. 173–190. doi:10.1515/9783110721447-009. Online
BibTeX
Abstract
Bubenhofer, Noah/Dreesen, Philipp (2022): Kollektivierungs- und Individualisierungseffekte. In: Diskurse – digital. De Gruyter. S. 173–190. doi:10.1515/9783110721447-009. Online
BibTeX
Abstract
Die Digitalisierung der Gesellschaft verändert gleichermaßen Prozesse der Konstruktion des Selbst und der Konstruktion von Gemeinschaften. Dies zeigt sich beispielsweise darin, dass Personen sowohl eine digitale Präsenz als klassische Website des Webs 1.0 als auch eine digitale Präsenz in den Medien des Webs 2.0 unterhalten können.
Diese Konstruktion des Selbst liegt allerdings nicht ausschließlich in den Händen des jeweiligen Individuums, z. B. indem es sein Facebook-Profil aktuellhält. Die Konstruktion des Selbst geschieht auch dadurch, dass die Digitalisierung in Form von verdatetem Handeln das individuelle und gesellschaftliche Handeln komplett durchdringt, indem beispielsweise laufend Datenspuren hinterlassen werden. In diesem Sinn lässt sich von einem digitalen Selbst sprechen.
Auch die Konstruktion von Gemeinschaften verläuft in der digitalen Gesellschaft in veränderter Form: Einerseits spielen digitale Medien in traditionellen Gemeinschaften wie Familien, Freundeskreisen etc. eine zentrale Rolle bei der Vergemeinschaftung. Andererseits bieten digitale Medien neue Formen der Vergemeinschaftung, die sich in an gemeinsamen Themen orientieren (z. B. in Online-Foren) oder die sich als Ergebnis digitalen Handelns von Individuen ergeben (z. B. durch algorithmische Vernetzung).
Grund für diese Veränderungen ist nach Couldry und Hepp (2017) die „tiefgreifende Mediatisierung“ („deep mediatization“) der Gesellschaft. Auf Basis dieser Diagnose kann nun abgeleitet werden, welche Konsequenzen dies für die Analyse digitaler Diskurse zeitigt. Wir schlagen im Folgenden vor, Kollektivierungs- und Individualisierungseffekte als analytische Dimension aufzufassen, die zentrale Aspekte der sozialen Ausprägung von Digitalität eröffnen. Ziel ist es, die soziologische Diagnose an eine linguistisch fundierte Analyse von Diskursen anschlussfähig zumachen.
The digitalisation of society equally changes processes of the construction of the self and the construction of communities. This can be seen, for example, in the fact that individuals can maintain both a digital presence as a classic website of the Web 1.0 and a digital presence in the media of the Web 2.0.
However, this construction of the self is not exclusively in the hands of the respective individual, e.g. by keeping their Facebook profile up to date. The construction of the self also happens through the fact that digitalisation in the form of digitalised action completely permeates individual and social action, for example, by constantly leaving data traces. In this sense, we can speak of a digital self.
The construction of communities also takes a different form in the digital society: On the one hand, digital media play a central role in the communalisation of traditional communities such as families, circles of friends, etc. On the other hand, digital media offer new forms of communitisation that are oriented towards common themes (e.g. in online forums) or that arise as a result of digital actions by individuals (e.g. through algorithmic networking).
According to Couldry and Hepp (2017), the reason for these changes is the "deep mediatisation" of society. Based on this diagnosis, we can now deduce what consequences this has for the analysis of digital discourses. In the following, we propose to understand collectivisation and individualisation effects as an analytical dimension that opens up central aspects of the social manifestation of digitality. The aim is to make the sociological diagnosis compatible with a linguistically based analysis of discourses.
La numérisation de la société modifie de la même manière les processus de construction de soi et de construction de communautés. Cela se traduit par exemple par le fait que les individus peuvent entretenir une présence numérique sous la forme d'un site web classique du Web 1.0 ainsi qu'une présence numérique dans les médias du Web 2.0.
Cette construction du soi n'est toutefois pas exclusivement entre les mains de l'individu concerné, par exemple en tenant son profil Facebook à jour. La construction du soi se fait également par le fait que la numérisation, sous forme d'actions datées, imprègne complètement les actions individuelles et sociales, en laissant par exemple des traces de données en permanence. En ce sens, on peut parler d'un soi numérique.
La construction de communautés se déroule également sous une forme modifiée dans la société numérique : D'une part, les médias numériques jouent un rôle central dans la communautarisation des communautés traditionnelles telles que les familles, les cercles d'amis, etc. D'autre part, les médias numériques offrent de nouvelles formes de communautarisation qui s'orientent vers des thèmes communs (par ex. dans les forums en ligne) ou qui résultent de l'action numérique des individus (par ex. par la mise en réseau algorithmique).
Selon Couldry et Hepp (2017), la raison de ces changements est la "médiatisation profonde" ("deep mediatization") de la société. Sur la base de ce diagnostic, il est maintenant possible de déduire les conséquences que cela entraîne pour l'analyse des discours numériques. Nous proposons ici de considérer les effets de collectivisation et d'individualisation comme une dimension analytique qui ouvre des aspects centraux de l'expression sociale du numérique. L'objectif est de rendre le diagnostic sociologique compatible avec une analyse linguistiquement fondée des discours.
Bender, Michael/Bubenhofer, Noah/Dreesen, Philipp/Georgi, Christopher/Rüdiger, Jan Oliver/Vogel, Friedemann (2022): Techniken und Praktiken der Verdatung. In: Diskurse – digital. De Gruyter. S. 135–158. doi:10.1515/9783110721447-007.
Online
BibTeX
Abstract
Fragen der Verdatung sind Bestandteil der digitalen Diskursanalyse und keine Vorarbeiten. Die Analyse digital(isiert)er Diskurse setzt im Unterschied zur Auswertung nicht-digital repräsentierter Sprache und Kommunikation notwendig technische Verfahren und Praktiken, Algorithmen und Software voraus, die den Untersuchungsgegenstand als digitales Datum konstituieren. Die nachfolgenden Abschnitte beschreiben kurz und knapp wiederkehrende Aspekte dieser Verdatungstechniken und -praktiken, insbesondere mit Blick auf Erhebung und Transformation (Abschnitt 2), Korpuskompilierung (Abschnitt 3), Annotation (Abschnitt 4) und Wege der analytischen Datenerschließung (Abschnitt 5). Im Fazit wird die Relevanz der Verdatungsarbeit für den Analyseprozess zusammengefasst (6).
Questions of data storage are part of digital discourse analysis and not preliminary work. The analysis of digitally(ised) discourses, unlike the analysis of non-digitally represented language and communication, necessarily presupposes technical procedures and practices, algorithms and software that constitute the object of study as digital datum. The following sections briefly and succinctly describe recurring aspects of these data-mining techniques and practices, particularly with regard to collection and transformation (section 2), corpus compilation (section 3), annotation (section 4) and ways of analytically indexing data (section 5). The conclusion summarises the relevance of the work of data mining for the analytical process (6).
Les questions de datation font partie intégrante de l'analyse du discours numérique et ne constituent pas un travail préparatoire. Contrairement à l'évaluation de la langue et de la communication non représentées numériquement, l'analyse des discours numériques (ou numérisés) présuppose nécessairement des procédures et des pratiques techniques, des algorithmes et des logiciels qui constituent l'objet d'étude en tant que donnée numérique. Les sections suivantes décrivent brièvement les aspects récurrents de ces techniques et pratiques de datation, notamment dans l'optique de la collecte et de la transformation (section 2), de la compilation de corpus (section 3), de l'annotation (section 4) et des manières d'exploiter les données de façon analytique (section 5). La conclusion résume la pertinence du travail de datation pour le processus d'analyse (6).
 Bubenhofer, Noah (2022): Exploration semantischer Räume im Corona-Diskurs. In: Kämper, Heidrun / Plewnia, Albrecht: Sprache in Politik und Gesellschaft. Jahrbuch des Instituts für Deutsche Sprache, 2021. Mannheim: 2022, S. 197-216. DOI: 10.1515/9783110774306-013. Online
Daten BibTeX
Abstract
Bubenhofer, Noah (2022): Exploration semantischer Räume im Corona-Diskurs. In: Kämper, Heidrun / Plewnia, Albrecht: Sprache in Politik und Gesellschaft. Jahrbuch des Instituts für Deutsche Sprache, 2021. Mannheim: 2022, S. 197-216. DOI: 10.1515/9783110774306-013. Online
Daten BibTeX
Abstract
Im Corona-Diskurs prallen vollig unterschiedliche Meinungen und Positionen zur Rolle des Staates aufeinander. Die Studie untersucht diese Positionen mit korpuslinguistischen Methoden anhand der Berichterstattung von Medien und Kommentaren von Leserinnen und Lesern in der Deutschschweiz. Dabei werden auch rechte und Corona-skeptische Plattformen in die Analyse einbezogen. Grundlage des korpuspragmatischen Zugangs ist die Berechnung und Interpretation von Word Embeddings, einer Methode zur Modellierung von semantischen Raumen. Es zeigt sich, wie sich im Diskurs inkommensurable Semantiken entwickeln.
In the Corona discourse, completely different opinions and positions on the role of the state clash. The study examines these positions using corpus linguistic methods on the basis of media coverage and comments by readers in German-speaking Switzerland. Right-wing and Corona-skeptic platforms are also included in the analysis. The corpuspragmatic approach is based on the calculation and interpretation of word embeddings, a method for modeling semantic spaces. It shows how incommensurable semantics develop in discourse.
Dans le discours de Corona, des opinions et des positions totalement différentes sur le rôle de l'Etat s'affrontent. L'étude examine ces positions à l'aide de méthodes de linguistique de corpus en se basant sur les reportages des médias et les commentaires des lecteurs en Suisse alémanique. Des plateformes de droite et sceptiques vis-à-vis de Corona sont également prises en compte dans l'analyse. La base de l'approche pragmatique du corpus est le calcul et l'interprétation des Word Embeddings, une méthode de modélisation des espaces sémantiques. Il en ressort comment des sémantiques incommensurables se développent dans le discours.
Bubenhofer, Noah/Knuchel, Daniel/Schüller, Larissa (2021): Kulturlinguistik in der Schweiz – eine Einführung in dieses Heft. In: Germanistik in der Schweiz, Sonderheft „Kulturlinguistik“ 18, DOI: 10.24894/1664-2457.00016. Online BibTeX
Bubenhofer, Noah/Knuchel, Daniel/Schüller, Larissa (2021): Digitale Kulturlinguistik: Digitalität als Gegenstand und Methode. In: Germanistik in der Schweiz, Sonderheft „Kulturlinguistik“ 18, DOI: 10.24894/1664-2457.00019. Online BibTeX
Bubenhofer, Noah (2021): Bilder in Vorlesungen, Hörsäle als Bilder: diagrammatische Überlegungen. In: Zeitschrift für germanistische Linguistik, 3/49, S. 596-622, 10.1515/zgl-2021-2040. Online
BibTeX
Abstract
Mit meinem Beitrag verfolge ich das Ziel, die Bildlichkeit im Zusammenhang von Vorlesungen theoretisch zu fassen. Das Ziel ist mit Bedacht vage formuliert, denn Bildlichkeit erscheint uns in vielen Formen, die sich auf drei Grundformen reduzieren lassen:
- Bilder in Vorlesungen
- Vorlesungen als Bilder
- Hörsäle als Bilder
Ich meine mit „Bild“ zudem nicht verbale Bildlichkeit, also mögliche Formen von Metaphorik, Sprachbildern etc., sondern verstehe Bilder als „diagrammatische Bilder“. Darunter fällt Grafisches in Form von Bildern oder grafisch gegliedertem Text, die die Rede einer Vorlesung begleiten, aber auch komplexe Settings von Rede und Objekten und Handlungen, mit denen gezeigt, demonstriert und generell interagiert wird.
Hintergrund dieser Herangehensweise ist die Diagrammatik, eine Theorie des Gebrauchs, der Formen und Funktionen von Diagrammen und Diagrammatischem. Damit meine ich, dass Objekt der Diagrammatik nicht nur grafische Inskriptionen auf Flächen (oder auch dreidimensional erlebbaren Räumen wie etwa Virtual Reality) sind, sondern dass die Diagrammatik es erlaubt, einen „diagrammatischen Blick“ auf Phänomene einzunehmen, der über die klassischen Diagramme hinaus reicht.
Ich werde im Folgenden zunächst die wichtigsten Elemente einer Diagrammatik ausbreiten, die für eine solche Betrachtungsweise von Vorlesungen notwendig sind. Danach werde ich anhand weniger historischer als auch gegenwärtiger Beispiele die drei Ebenen des Diagrammatischen ausführen: Diagrammatisches in Vorlesungen, Vorlesungen als Diagramme und Hörsäle als Diagramme.
Damit möchte ich anregen, Vorlesungspraktiken diagrammatisch zu betrachten und vor allem auch historische Veränderungen dieser Praktiken als Veränderungen diagrammatischer Ordnungen zu beschreiben.
With my contribution I pursue the goal of theoretically grasping pictoriality in the context of lectures. The aim is deliberately vague, because pictoriality appears to us in many forms, which can be reduced to three basic forms:
- Images in lectures
- Lectures as pictures
- Lecture halls as pictures
Moreover, by "image" I do not mean verbal pictoriality, i.e. possible forms of metaphors, linguistic images, etc., but understand images as "diagrammatic images". This includes graphic things in the form of images or graphically structured text that accompany the speech of a lecture, but also complex settings of speech and objects and actions that are used to show, demonstrate, and generally interact.
The background of this approach is diagrammatics, a theory of the use, forms and functions of diagrams. By this I mean that the object of diagrammatics is not only graphical inscriptions on surfaces (or even spaces that can be experienced in three dimensions, such as virtual reality), but that diagrammatics allows us to take a "diagrammatic view" of phenomena that extends beyond classical diagrams.
In what follows, I will first unfold the main elements of a diagrammatics that are necessary for such a way of looking at lectures. After that, I will elaborate on the three levels of diagrammaticality by means of a few historical as well as contemporary examples: Diagrammatics in lectures, lectures as diagrams, and lecture halls as diagrams.
.
In doing so, I would like to suggest that lecture practices be considered diagrammatically and, more importantly, that historical changes in these practices be described as changes in diagrammatic orders.
Avec ma contribution, je poursuis l'objectif de saisir théoriquement la picturalité dans le contexte des conférences. L'objectif est volontairement vague, car l'imagerie nous apparaît sous de nombreuses formes que l'on peut réduire à trois formes de base :
.
- Images dans les conférences
- Les conférences en images
- Les auditoriums comme images
En outre, par "image", je n'entends pas l'imagerie verbale, c'est-à-dire les formes possibles de métaphore, l'imagerie linguistique, etc., mais j'entends les images comme des "images diagrammatiques". Il s'agit notamment de matériel graphique sous forme d'images ou de textes structurés graphiquement qui accompagnent le discours d'une conférence, mais aussi de mises en scène complexes de discours et d'objets et d'actions qui sont utilisés pour montrer, démontrer et généralement interagir.
Le contexte de cette approche est la diagrammatique, une théorie de l'utilisation, des formes et des fonctions des diagrammes et des schémas. Je veux dire par là que l'objet de la diagrammatique n'est pas seulement des inscriptions graphiques sur des surfaces (ou même des espaces pouvant être vécus en trois dimensions, comme la réalité virtuelle), mais que la diagrammatique nous permet d'adopter une "vision diagrammatique" des phénomènes qui s'étend au-delà des diagrammes classiques.
Dans ce qui suit, j'exposerai d'abord les éléments les plus importants d'un diagramme qui sont nécessaires pour une telle façon de voir les cours. Ensuite, je développerai les trois niveaux du diagramme à l'aide d'exemples moins historiques et plus contemporains : Des diagrammes dans les conférences, des conférences comme des diagrammes et des auditoriums comme des diagrammes.
De cette façon, je voudrais encourager une vision schématique des pratiques de lecture et, surtout, décrire les changements historiques de ces pratiques comme des changements dans les ordres schématiques.
 Tissot, Fabienne / Bubenhofer, Noah (2020): Diskurslinguistik in der Praxis. Ein wissenssoziologischer Blick auf die Herausforderungen transdiziplinären Arbeitens. In: Dreesen, Philip / Stücheli-Herlach, Peter: Transdisziplinarität der Diskurslinguistik. Sonderheft Zeitschrift für Diskurslinguistik, 2-3, S. 141-163. Online (kostenpflichtig) BibTeX
Tissot, Fabienne / Bubenhofer, Noah (2020): Diskurslinguistik in der Praxis. Ein wissenssoziologischer Blick auf die Herausforderungen transdiziplinären Arbeitens. In: Dreesen, Philip / Stücheli-Herlach, Peter: Transdisziplinarität der Diskurslinguistik. Sonderheft Zeitschrift für Diskurslinguistik, 2-3, S. 141-163. Online (kostenpflichtig) BibTeX
 Bubenhofer, Noah (2021): Masken und Küsschen: Korpuslinguistische Exploration des Corona-Diskurses in der Deutschschweiz. In: Mitteilungen des Deutschen Germanistenverbandes 68 (2), S. 127-140, DOI: 10.14220/mdge.2021.68.2.127.
Online (kostenpflichtig)
BibTeX
Abstract
Bubenhofer, Noah (2021): Masken und Küsschen: Korpuslinguistische Exploration des Corona-Diskurses in der Deutschschweiz. In: Mitteilungen des Deutschen Germanistenverbandes 68 (2), S. 127-140, DOI: 10.14220/mdge.2021.68.2.127.
Online (kostenpflichtig)
BibTeX
Abstract
In der Linguistik gibt es seit mehreren Jahrzehnten ein großes Interesse für Alltagserzählungen. Begründet wurde diese Forschungstradition durch Untersuchungen von Labov/Waletzky (1973), die eine Erzähltheorie auf der Basis von Erzählungen über Krisenerlebnisse im Alltag entwickelten. Ihr Interesse lag dabei aber nicht bei der Analyse der einzelnen Geschichten, sondern bei der Herausarbeitung von Erzählmustern. Wie sind solche Erzählungen typischerweise strukturiert? Welche Erzählfunktionen und damit verbundenen Phasen finden sich in den Erzählungen? Aktuelle korpuslinguistische Ansätze erlauben einen neuen Blick auf Erzählmuster, besonders Ansätze, die korpuspragmatisch vorgehen. Unter Korpuspragmatik verstehe ich Ansätze, die Muster an der sprachlichen Oberfläche als Spuren sprachlichen Handelns deuten und beispielsweise für diskurs- und kulturlinguistische Forschungsfragen eingesetzt werden (Bubenhofer 2009, Bubenhofer/Scharloth 2013, Felder et al. 2011, Scharloth 2018). Besonders fruchtbar sind in diesem Zusammenhang datengeleitete Methoden der Korpusanalyse, die in einem ersten Schritt versuchen, unterschiedliche Typen von Musterhaftigkeit des Sprachgebrauchs in großen Datenmengen zu identifizieren. Diese Sprachgebrauchsmuster müssen dann in einem zweiten Schritt unter der Perspektive der jeweiligen Forschungsfrage gedeutet werden, was zu Hypothesen führt, die hinterher ggf. wieder mit anderen Methoden geprüft oder auf ihre Plausibilität hinterfragt werden können.
Im Folgenden möchte ich von solchen korpuspragmatischen Explorationen berichten, und zwar anhand des Corona-Diskurses in der Schweiz in der Zeit von Februar 2020 bis Ende Januar 2021. Doch wo werden zu diesem Thema Geschichten erzählt? Da auch ich mich für Erzählmuster interessiere, müssen die zu untersuchenden Erzählungen zahlreich sein, um Musterhaftigkeiten ableiten zu können. Gleichzeitig gilt das Interesse aber nicht nur der Musterhaftigkeit vieler Einzelerzählungen, sondern den überindividuellen, gesellschaftlichen Erzählungen im Corona-Diskurs. Eine interessante Quelle für diese Perspektive sind massenmedial verteilte Erzählungen, wie sie im „user generated content“ auf Newsplattformen entstehen, also in Kommentaren von Leserinnen und Lesern auf Plattformen von Online-Zeitungen. Unser COVID-19-UZH-Korpus umfasst über 800.000 solcher Kommentare zu Corona-Artikeln auf fünf Newsportalen der Deutschschweiz. Auf den ersten Blick scheinen Kommentare nicht die geeignete Textsorte zu sein, um darin Erzählungen zu finden. Die folgende Analyse zeigt aber, dass Erzählungen als Teil von Argumentation eine wichtige Rolle spielen. Mit Methoden der distributionellen Semantik wird in den Daten nach Spuren des Erzählens gesucht und die Funktion dieser Erzählungen gedeutet.
In linguistics, there has been a great interest in everyday narratives for several decades. This research tradition was founded by studies of Labov/Waletzky (1973), who developed a narrative theory on the basis of stories about crisis experiences in everyday life. Their interest, however, was not in the analysis of individual stories, but in the elaboration of narrative patterns. How are such narratives typically structured? What narrative functions and associated phases are found in the narratives? Current corpus linguistic approaches allow a new look at narrative patterns, especially approaches that take a corpus pragmatic approach. By corpus pragmatics I mean approaches that interpret patterns on the linguistic surface as traces of linguistic action and are used, for example, for discourse and cultural linguistic research questions (Bubenhofer 2009, Bubenhofer/Scharloth 2013, Felder et al. 2011, Scharloth 2018). Particularly fruitful in this context are data-driven methods of corpus analysis, which in a first step attempt to identify different types of patterned language use in large datasets. These patterns of language use then have to be interpreted in a second step under the perspective of the respective research question, which leads to hypotheses that can be tested again afterwards, if necessary, with other methods or questioned for their plausibility.
In the following, I would like to report on such corpuspragmatic explorations, using the Corona discourse in Switzerland in the period from February 2020 to the end of January 2021. But where are stories told on this topic? Since I am also interested in narrative patterns, the narratives to be studied must be numerous in order to derive patternedness. At the same time, however, the interest is not only in the patternedness of many individual narratives, but in the supra-individual, social narratives in Corona discourse. An interesting source for this perspective are mass media distributed narratives as they emerge in "user generated content" on news platforms, i.e. in comments of readers on platforms of online newspapers. Our COVID-19-UZH corpus comprises more than 800,000 such comments on Corona articles on five news portals in German-speaking Switzerland. At first glance, comments do not seem to be the appropriate text type to find narratives in. However, the following analysis shows that narratives play an important role as part of argumentation. Methods of distributional semantics are used to search for traces of narration in the data and to interpret the function of these narratives.
En linguistique, les récits quotidiens suscitent un grand intérêt depuis plusieurs décennies. Cette tradition de recherche a été fondée par Labov/Waletzky (1973), qui ont développé une théorie narrative basée sur des récits d'expériences de crise dans la vie quotidienne. Ils n'étaient cependant pas intéressés par l'analyse d'histoires individuelles, mais par l'élaboration de modèles narratifs. Comment ces récits sont-ils généralement structurés ? Quelles sont les fonctions narratives et les phases associées que l'on retrouve dans les récits ? Les approches actuelles de la linguistique de corpus permettent de jeter un nouveau regard sur les schémas narratifs, en particulier les approches qui procèdent par corpus de manière pragmatique. Par pragmatique de corpus, j'entends les approches qui interprètent les modèles sur la surface linguistique comme des traces de l'action linguistique et qui sont utilisées, par exemple, pour des questions de recherche sur le discours et la linguistique culturelle (Bubenhofer 2009, Bubenhofer/Scharloth 2013, Felder et al. 2011, Scharloth 2018). Dans ce contexte, les méthodes d'analyse de corpus axées sur les données sont particulièrement fructueuses. Dans un premier temps, elles tentent d'identifier différents types d'utilisation structurée de la langue dans de grands ensembles de données. Ces modèles d'utilisation de la langue doivent ensuite être interprétés dans une deuxième étape du point de vue de la question de recherche respective, ce qui conduit à des hypothèses qui peuvent ensuite être testées à nouveau avec d'autres méthodes si nécessaire ou remises en question pour leur plausibilité.
.
Dans ce qui suit, j'aimerais rendre compte de telles explorations corpuspragmatiques, en utilisant le discours de Corona en Suisse pendant la période de février 2020 à fin janvier 2021. Mais où sont les histoires racontées sur ce sujet ? Puisque je m'intéresse également aux schémas narratifs, les récits à examiner doivent être nombreux afin de pouvoir dériver des schémas. En même temps, l'intérêt ne porte pas seulement sur le caractère structuré de nombreux récits individuels, mais aussi sur les récits sociaux supra-individuels du discours de Corona. Les récits distribués par les médias de masse, tels qu'ils apparaissent dans le " user generated content " sur les plateformes d'information, c'est-à-dire dans les commentaires des lecteurs sur les plateformes de journaux en ligne, constituent une source intéressante pour cette perspective. Notre corpus COVID-19-UZH comprend plus de 800 000 commentaires sur des articles Corona sur cinq portails d'information en Suisse alémanique. À première vue, les commentaires ne semblent pas être le type de texte approprié pour trouver des récits. Cependant, l'analyse suivante montre que les récits jouent un rôle important dans l'argumentation. Des méthodes de sémantique distributionnelle sont utilisées pour rechercher des traces de narration dans les données et pour interpréter la fonction de ces narrations.
Bubenhofer, Noah (2020): Semantische Äquivalenz in Geburtserzählungen: Anwendung von Word Embeddings. In: Zeitschrift für germanistische Linguistik 48 (3), S. 562–589, doi: 10.1515/zgl-2020-2014. Online (PDF) BibTeX
Abstract
Die vorliegende Studie konzentriert sich auf seriell auftretende Erzählungen des "alltäglichen" Lebens, genauer gesagt auf Geburtserzählungen von Müttern in Online-Foren; die zugrunde liegende Idee ist, dass diese Erzählungen vor dem Hintergrund kultureller Erzählungen stattfinden.
In der vorliegenden Arbeit werden Modelle zur Worteinbettung verwendet, um typische Themen und Akteure in diesen Erzählungen zu erkennen. Durch die Berechnung von Worteinbettungen werden automatisch semantische Räume konstruiert, in denen semantische Beziehungen (insbesondere Synonymie) modelliert werden können. Diese Methode bietet eine Möglichkeit, Synonymie als "funktionale Äquivalenz im Diskurs" zu betrachten.
Die vorliegende Studie stützt sich auf frühere Arbeiten mit N-Grammen (Bubenhofer, 2018). N-Gramme sind Sequenzen von Wörtern, die häufig zusammen auftreten; ihre Reihenfolge in verschiedenen Erzählungen gibt Aufschluss über narrative Muster. Ein weiterer Schritt in der Analyse ist die Konstruktion von "narrativen Topoi", die durch Clustering benachbarter Vektoren erreicht wird. Die entstehenden Cluster können wiederum in fünf narrative Elemente des "Erzählens einer Geburtsgeschichte" gruppiert werden: 1) Einbruch in den Alltag, 2) Personal, 3) Körper, 4) Angst, 5) Freude. Während es offensichtlich scheint, dass bestimmte Themen in die Erzählung einer Geburt "gehören", ist es weniger offensichtlich, mit welchem Vokabular diese Themen ausgedrückt werden.
Die hier vorgestellte Methode des Clusterns von Worteinbettungs-Profilen ist eine enorme Bereicherung für die Modellierung einer Erzählung. Ihre Vorteile liegen in ihrem Potenzial, lexikalische Variation aufzuzeigen, da sie auch seltene, nicht konforme orthographische Varianten einbezieht. Darüber hinaus ermöglicht es eine diskursspezifische (und gebrauchsbasierte) Sicht auf semantische Relationen. Dasselbe gilt für die Beziehungen zwischen semantischen Clustern. Aus der Perspektive der Diskurslinguistik oder der Kulturanalyse erneuern Worteinbettungen unser Verständnis von Semantik. Dies erweist sich als besonders fruchtbar, wenn sie zur Analyse von (diskursabhängigen) Differenzen zwischen semantischen Räumen verwendet werden.
The present study focuses on serially occurring narrations of ‘everyday’ life, more specifically on birthing as narrated by mothers on online forums; the underlying idea being that these narrations happen against the background of cultural narratives.
The present paper uses word embedding models to detect typical topics and actors in these narrations. The calculation of word embeddings automatically constructs semantic spaces, where semantic relations (synonymy in particular) can be modeled. This method offers a way to think of synonymy as ‘functional equivalence in discourse’.
The present study relies on previous work with n-grams (Bubenhofer, 2018). N-grams are sequences of words that often appear together; their sequential order in different narrations gives insight in narrative patterns. A further step in the analysis is the construction of ‘narrative topoi’, which is achieved through clustering neighboring vectors. The emerging clusters can in turn be grouped into five narrative elements of ‘telling a birth story’: 1) disruption of daily life, 2) personnel, 3) body, 4) fear, 5) joy. While it seems obvious that certain themes ‘belong’ into the narration of a delivery, it is less obvious with what vocabulary these themes are expressed.
The presented method of clustering word-embedding-profiles adds tremendously to the modelling of a narrative. Its advantages lie in its potential to show lexical variation, as it also includes rare, non-conformative orthographical variants. Furthermore, it allows for a discourse-specific (and usage-based) view on semantic relations. The same applies to relations between semantic clusters. Seen from a discourse linguistics or cultural analysis perspective, word embeddings renew our understanding of semantics. This shows particularly fruitful if used to analyze (discourse dependent) derivations between semantic spaces.
Cette étude se concentre sur les narrations de la vie quotidienne qui se produisent en série. L'idée fondamentale est que ces récits s'inscrivent dans le contexte de récits culturels.
Dans cet article, des modèles d'intégration de mots (Word Embeddings) sont utilisés pour identifier les thèmes et les acteurs typiques de ces narrations. En calculant les encastrements de mots, on construit automatiquement des espaces sémantiques dans lesquels les relations sémantiques (en particulier la synonymie) peuvent être modélisées. Cette méthode permet d'envisager la synonymie comme une "équivalence fonctionnelle dans le discours".
Cette étude s'inspire de travaux antérieurs sur les N-grams (Bubenhofer, 2018). Les N-grammes sont des séquences de mots qui apparaissent fréquemment ensemble ; leur ordre dans différents récits fournit des informations sur les modèles narratifs. Une autre étape de l'analyse est la construction d'un "topoï narratif", qui est réalisé en regroupant des vecteurs voisins. Les groupes qui en résultent peuvent à leur tour être regroupés en cinq éléments narratifs de "raconter une naissance" : 1) intrusion dans la vie quotidienne, 2) personnel, 3) corps, 4) peur, 5) joie. S'il semble évident que certains thèmes " appartiennent " au récit d'une naissance, il est moins évident de savoir quel vocabulaire est utilisé pour exprimer ces thèmes.
La méthode de regroupement des profils d'intégration des mots présentée ici est un atout considérable pour la modélisation d'un récit. Ses avantages résident dans son potentiel à révéler la variation lexicale, puisqu'il inclut également les variantes orthographiques rares et non conformes. De plus, elle permet une vision des relations sémantiques spécifique au discours (et basée sur l'usage). Il en va de même pour les relations entre les clusters sémantiques. Du point de vue de la linguistique du discours ou de l'analyse culturelle, les encastrements de mots renouvellent notre compréhension de la sémantique. Cette méthode s'avère particulièrement fructueuse lorsqu'elle est utilisée pour analyser les différences (dépendant du discours) entre les espaces sémantiques.
 Knuchel, Daniel/Bubenhofer, Noah (2020): Korpuslinguistische Expeditionen als Anregung zur Reflexion über Sprachgebrauch – Forschendes Lernen mit dem DWDS und dem DeReKo. In: Der Deutschunterricht (6), S. 63–76.
Online (kostenpflichtig) BibTeX
Abstract
Knuchel, Daniel/Bubenhofer, Noah (2020): Korpuslinguistische Expeditionen als Anregung zur Reflexion über Sprachgebrauch – Forschendes Lernen mit dem DWDS und dem DeReKo. In: Der Deutschunterricht (6), S. 63–76.
Online (kostenpflichtig) BibTeX
Abstract
Frei zugängliche Datenkorpora wie das Digitale Wörterbuch der deutschen Sprache, DWDS oder das Deutsche Referenzkorpus, DeReKo besitzen ein enormes Potenzial für das Forschende Lernen in schulischen Kontexten. In dem Beitrag wird aufgezeigt, wie korpuslinguistische Tools eingesetzt werden können, um die Lernenden zum Nachdenken über gesellschaftlich geprägten und individuellen Sprachgebrauch anzuregen.
 Bubenhofer, Noah/Knuchel, Daniel/Sutter, Livia/Kellenberger, Maaike/Bodenmann, Niclas (2020): Von Grenzen und Welten: Eine korpuspragmatische COVID-19-Diskursanalyse. In: Aptum. Zeitschrift für Sprachkritik und Sprachkultur 02/03 (16), S. 46–55, DOI: 10.46771/978-3-96769-102-3_7. Download PDF
BibTeX
Bubenhofer, Noah/Knuchel, Daniel/Sutter, Livia/Kellenberger, Maaike/Bodenmann, Niclas (2020): Von Grenzen und Welten: Eine korpuspragmatische COVID-19-Diskursanalyse. In: Aptum. Zeitschrift für Sprachkritik und Sprachkultur 02/03 (16), S. 46–55, DOI: 10.46771/978-3-96769-102-3_7. Download PDF
BibTeX
Dreesen, Philipp/Bubenhofer, Noah: Das Konzept «Übersetzen» in der digitalen Transformation. In: Germanistik in der Schweiz (2020), Nr. 16, 26-49, DOI: 10.24894/1664-2457.00003. Online (PDF)
BibTeX
Abstract
Der Prozess des Übersetzens ändert sich derzeit grundlegend. Maschinelles Übersetzen / machine translation (MT) natürlichsprachlicher Sätze und Texte hat in den vergangenen Jahren insbesondere durch den Einsatz künstlicher Intelligenz enorme Dynamiken entfaltet. Für einen grossen Teil der Endanwender*innen in unserer Gesellschaft bedeutet dies eine starke Vereinfachung: Fremdsprachige Textelemente lassen sich dank Diensten wie google-Translate und DeepL schnell und kostengünstig in beachtlicher Qualität übersetzen. Insofern erscheint den meisten Menschen diese neue Form des Übersetzens als Ergebnis des technischen Fortschritts.
Auf der anderen Seite wird rege diskutiert, was die Rolle menschlicher Übersetzung sein soll: Einerseits wird auf die qualitativen Mängel maschineller Übersetzung verwiesen und hervorgehoben, worin der Mehrwert menschlicher Übersetzungen liegt; andererseits wird argumentiert, dass Mensch und Maschine sich gegenseitig ergänzen und so zu effizienteren und besseren Übersetzungen kommen können.
Diskussionen über das Übersetzen können als metasprachliche, also sprachreflexive, Diskurse angesehen werden, denn es werden Aussagen über sprachliches Handeln getroffen (Kapitel 2). Darüber hinaus kann das Übersetzen selber im Anschluss an Spitzmüller (2019) als Metapragmatik bezeichnet werden. Denn Übersetzen ist eine sprachliche Praxis, die die Sprachverwendung eines Ausgangstextes reflektiert und daraus neue Sprachhandlungen produziert, nämlich den übersetzten Text.
Dieses metapragmatische Handeln konstruiert eine bestimmte Vorstellung von Sprache, z. B. dass ein Ausgangstext in einer Einzelsprache vorliegt und in eine andere Einzelsprache übersetzt werden kann. Das metapragmatische Handeln findet also in einem bestimmten Handlungsrahmen statt, in dem bestimmte Sprachideologien dominieren. Diese können aber sehr unterschiedlich ausfallen und es ist anzunehmen, dass menschliche Übersetzer*innen in einem anderen Handlungsrahmen agieren als z. B. Computerlinguist*innen, die ein maschinelles Übersetzungssystem trainieren. Im Folgenden möchten wir argumentieren, dass es lohnenswert ist, Übersetzen als metapragmatischen Diskurs aufzufassen und die zugrundeliegenden Sprachideologien freizulegen.
Ein zweiter Aspekt betrifft die Wahrnehmung der sprachideologischen Veränderungen, die mit dem enormen technischen Wandel einhergehen (Kapitel 3). Denn so deutlich vernehmbar die Veränderung des Umgangs mit unterschiedlichen Sprachen im privaten und beruflichen Alltag ist, so wenig wahrnehmbar sind die Triebfedern hinter den digitalen Angeboten. Wir haben es mit dem paradoxen Fall einer sichtbaren und zugleich unsichtbaren Veränderung zu tun: Je mehr wir MT nutzen und als selbstverständlich anzunehmen, desto schneller verschwindet MT aus unserer Wahrnehmung.
Ausgehend von dieser Beobachtung und Prognose möchten wir im Folgenden argumentieren, dass es dringend erforderlich ist, die digitale Transformation des Übersetzens linguistisch zu reflektieren (Kapitel 4). Die sprachideologischen Veränderungen hinter den Übersetzungsdiskursen in Kombination mit dem Paradox der Un- und Sichtbarkeit der Veränderung wirken sich dabei nicht nur auf die Konzeption von Übersetzen aus, sondern auf die humanistische Vorstellung von Mehrsprachigkeit ganz generell (Kapitel 5).
 Bubenhofer, Noah/Calleri, Selena/Dreesen, Philipp (2019): Politisierung in rechtspopulistischen Medien: Wortschatzanalyse und Word Embeddings. In: OBST. Osnabrücker Beiträge zur Sprachtheorie, Nr. 95, 211-242. Online (PDF)
BibTeX
Abstract
Bubenhofer, Noah/Calleri, Selena/Dreesen, Philipp (2019): Politisierung in rechtspopulistischen Medien: Wortschatzanalyse und Word Embeddings. In: OBST. Osnabrücker Beiträge zur Sprachtheorie, Nr. 95, 211-242. Online (PDF)
BibTeX
Abstract
Ausgehend von der politischen Selbstverortung von PI-NEWS und COMPACT Online werden mittels Topoi-Analyse diese Medien als Orte der Aufklärung und des Widerstands gegen Bedrohungen des Volkes bestimmt. Dies mündet im Beitrag in ein vorläufiges Rechtspopulismuskonzept. Ein Korpus aus diesen rechtspopulistischen Medientexten und ein Korpus aus Texten deutscher Orientierungsmedien werden so aufeinander bezogen, dass in Wortschatzanalysen und Word Embedding-Modellen spezifische Politisierungen im Wortgebrauch nachweisbar sind. Im Ergebnis kann mithilfe von Kollokationsberechnungen gezeigt werden, dass im Sprachgebrauch des Rechtspopulismus auch politisch völlig unspezifische Wörter kontextuell eindeutig ideologisch politisiert werden.
 Bubenhofer, Noah (2019): Social Media und der Iconic Turn: Diagrammatische Ordnungen im Web 2.0. In: Diskurse – digital 1, S. 114-135, DOI: 10.25521/diskurse-digital.2019.107. Online (PDF)
BibTeX
Abstract
Bubenhofer, Noah (2019): Social Media und der Iconic Turn: Diagrammatische Ordnungen im Web 2.0. In: Diskurse – digital 1, S. 114-135, DOI: 10.25521/diskurse-digital.2019.107. Online (PDF)
BibTeX
Abstract
Die beiden zentralen Forderungen des Iconic Turns sind, 1) das Bildhafte an kulturellem Handeln anzuerkennen, aber auch 2) Bilder als Analyseinstrument von Kultur zu nutzen. Es geht um eine Rehabilitierung des Visuellen in seiner weitesten Bedeutung, verbunden mit der Erkenntnis, dass Bilder maßgeblich kulturelles Handeln prägen.
Als Korpuslinguist ist man immer wieder mit dem Vorwurf konfrontiert, mit der Analyse von Textkorpora ebendiese Visualität sträflich zu vernachläßigen. Wenn man beispielsweise Diskurse in Sozialen Medien wie Twitter, Facebook, Instagram u.ä. untersucht, sind diese ohne Zweifel von einer reichen Praxis der Bildbenutzung, Bildzitation etc. durchdrungen. Das stellt korpus- und computerlinguistische Untersuchungen von Social-Media-Daten, wie z.B. sog. Sentiment-Analysen, die große Mengen von Twitter-Tweets auf ihre Tonalität hin untersuchen, vor Probleme. Denn, um nur ein Minimalbeispiel zu geben, kann ein Text begleitendes Bild die Tonalität eines Tweets grundsätzlich ändern. Gar nicht erfasst werden zudem textlose, nur aus einem Bild bestehende Tweets, die genauso als Zeichen eine Tonalität entfalten können.
Weniger quantitativ ausgerichtete linguistische Analysen berücksichtigen jedoch die Bildlichkeit solcher Daten weit stärker, wie verschiedene multimodale Analysen zeigen (Frank-Job u. a., 2013; Seizov/Wildfeuer, 2017; Zappavigna, 2018; grundsätzlich: Page u. a., 2014, S. 16). Sie können beispielsweise verdeutlichen, wie Tweets als multimodale Zeichen, die zitiert, rekontextualisiert und modifiziert werden, diskursive Kräfte entfalten.
Mit den folgenden Überlegungen möchte ich aber einen nochmals anders gelagerten Aspekt von Bildlichkeit in sozialen Medien thematisieren: Dabei geht es nicht um Bilder im Sinne von Fotos, Zeichnungen, Filmen etc. als Bestandteile von Posts, sondern um diagrammatische Bildlichkeit, die die Darstellungen und Ordnungen von Texten, Postings und allen anderen Zeichen in sozialen Medien organisieren. Diese diagrammatische Bildlichkeit geht zurück auf diagrammatische Grundfiguren wie Listen, Netze, Karten oder Partituren. So erscheinen Tweets in einer „Timeline“ als geordnete Liste, die jedoch z.B. über die Auswahl eines Hashtags anders geordnet wird.
Der springende Punkt bei den Überlegungen ist dabei, dass die Analysen von Sozialen Medien wiederum selber diagrammatische Operationen vornehmen und so neue Ordnungen rekonstruieren. Verfolgt man ein diskursanalytisches Interesse bei der Analyse solcher Daten, ist das Zusammenspiel von „präanalytischen“ und analytischen diagrammatischen Operationen ein nicht zu trennendes Ensemble der gemeinsamen Rekonstruktion von Diskursen.
 Bubenhofer, Noah/Rossi, Michela (2019): Die Migrationsdiskurse in Italien und der Deutschschweiz im korpuslinguistischen Vergleich. In: Goranka, R./Schafroth, E. (Hrsg.): Vergleichende Diskurslinguistik. Methoden und Forschungspraxis. (Kontrastive Linguistik 9) Berlin: Peter Lang, S. 153-192.
Online (PDF)
BibTeX
Abstract
Bubenhofer, Noah/Rossi, Michela (2019): Die Migrationsdiskurse in Italien und der Deutschschweiz im korpuslinguistischen Vergleich. In: Goranka, R./Schafroth, E. (Hrsg.): Vergleichende Diskurslinguistik. Methoden und Forschungspraxis. (Kontrastive Linguistik 9) Berlin: Peter Lang, S. 153-192.
Online (PDF)
BibTeX
Abstract
Korpuslinguistische Arbeitsweisen bei Diskursanalysen haben sich in den letzten Jahren als äußerst fruchtbar erwiesen. Bei sprachkontrastiven Analysen, etwa wenn Diskurse zum gleichen Thema in zwei unterschiedlichen Sprachregionen untersucht werden sollen, stellt sich jedoch immer das Problem, wie maschinelle Analysen in Korpora unterschiedlicher Sprache verglichen werden können.
Bei unserem Vorschlag arbeiten wir zusätzlich zu einem italienisch- und einem deutschsprachigen Korpus von Pressemitteilungen der wichtigsten Parteien in Italien und der Deutschschweiz mit einem Parallelkorpus Deutsch-Italienisch, um mit automatischen Methoden die in den jeweiligen Sprachen typischen Lexeme zueinander in Beziehung setzen zu können. Interessant ist dabei beispielsweise zu sehen, wie in den Diskursen wichtige Konzepte in die jeweils andere Sprache übersetzt werden könnten – und ob sie tatsächlich so in der anderen Sprache vorkommen. Daneben nutzen wir klassische Analyseansätze wie n-Gramm- und Kollokationsanalysen, um den wichtigen Topoi und Argumentationsmustern im aktuellen Migrationsdiskurs auf die Spur zu kommen und die Unterschiede und Gemeinsamkeiten der Diskurse in den beiden Ländern vergleichen zu können.
 Bubenhofer, Noah/Rothenhäusler, Klaus/Affolter, Katrin/Pajovic, Danica (2019): The Linguistic Construction of World – an Example of Visual Analysis and Methodological Challenges. In: Scholz, Ronny (Hrsg.): Quantifying Approaches to Discourse for Social Scientists. Basingstoke: Palgrave Macmillan. 251-284. DOI: 10.1007/978-3-319-97370-8_9. Online
BibTeX
Abstract
Bubenhofer, Noah/Rothenhäusler, Klaus/Affolter, Katrin/Pajovic, Danica (2019): The Linguistic Construction of World – an Example of Visual Analysis and Methodological Challenges. In: Scholz, Ronny (Hrsg.): Quantifying Approaches to Discourse for Social Scientists. Basingstoke: Palgrave Macmillan. 251-284. DOI: 10.1007/978-3-319-97370-8_9. Online
BibTeX
Abstract
In this article we discuss common approaches to using data visualizations within the field of digital humanities. We argue that by assigning equal importance to the development, as well as the usage of a visualization framework, researchers can question dogmatic “best-practice” norms for data visualizations which may prevent them from developing visualizations that can be used to find emergent phenomena within the underlying data. We then focus on the question, how visualizations re-constitute language by using diagrammatic operations. Also of big importance working with digital visualizations is the technological background influencing the tools built with and the effect on the interpretation of the data. As an example approach, we present our visualization framework called “geocollocations” which can be used as an interactive tool to detect words that typically collocate with toponyms based on the data of various text corpora.
2018
 Bubenhofer, Noah (2018): Diskurslinguistik und Korpora. In: Warnke, Ingo (Hrsg.): Handbuch Diskurs, Sprachwissen. Berlin / New York: De Gruyter, S. 208-241, DOI: 10.1515/9783110296075-009.
Code auf GitHub (diatopics)
Online (PDF)
BibTeX
Abstract
Bubenhofer, Noah (2018): Diskurslinguistik und Korpora. In: Warnke, Ingo (Hrsg.): Handbuch Diskurs, Sprachwissen. Berlin / New York: De Gruyter, S. 208-241, DOI: 10.1515/9783110296075-009.
Code auf GitHub (diatopics)
Online (PDF)
BibTeX
Abstract
Der Beitrag skizziert die grundsätzliche korpuslinguistische Perspektive auf Diskurse. Zunächst wird diese Perspektive genauer spezifiziert als Fokussierung auf die Musterhaftigkeit von Sprache und Repräsentation von Daten in Vektorräumen. Danach werden die grundlegenden Schritte des Korpusaufbaus und die Möglichkeiten der Annotation der Daten diskutiert. Schließlich werden die wichtigsten Analysekategorien, die für diskurslinguistische Fragestellungen relevant sind, beschrieben: Kollokationen, Mehrworteinheiten, Keywords, Topic Models und Netzwerkanalysen. Der Beitrag schließt mit Überlegungen, die Korpuslinguistik nicht als Hilfswissenschaft für die Diskursanalyse zu sehen, sondern als Schlüssel zu einem neuen Verständnis des Umgangs mit Daten in den Geisteswissenschaften. In diesem Zusammenhang werden fünf Desiderate genannt, die im Rahmen einer sozial und kulturwissenschaftlich interessierten maschinellen Textanalyse verfolgt werden sollten.
 Bubenhofer, Noah (2018): Visualisierungen in der Korpuslinguistik.
Diagrammatische Operationen zur Gegenstandkonstitution, -analyse und Ergebnispräsentation. In: Kupietz, Marc / Schmidt, Thomas (Hrsg.): Korpuslinguistik, Germanistische Sprachwissenschaft um 2020 (5). Berlin, Boston: De Gruyter, S. 27–60, DOI: 10.1515/9783110538649-003.
Online (PDF)
BibTeX
Abstract
Bubenhofer, Noah (2018): Visualisierungen in der Korpuslinguistik.
Diagrammatische Operationen zur Gegenstandkonstitution, -analyse und Ergebnispräsentation. In: Kupietz, Marc / Schmidt, Thomas (Hrsg.): Korpuslinguistik, Germanistische Sprachwissenschaft um 2020 (5). Berlin, Boston: De Gruyter, S. 27–60, DOI: 10.1515/9783110538649-003.
Online (PDF)
BibTeX
Abstract
Visualisierungen sind auch in der Korpuslinguistik wichtig, um Strukturen in großen Korpora überhaupt analysierbar zu machen. Daher sind Methoden der “Visual Analytics” nicht einfach der letzte Schritt einer Korpusanalyse, sondern beein ussen bereits die Datenaufbereitung. Aus Sicht der Diagrammatik, der Lehre des Diagramms, lässt sich gut herleiten, warum Visualisierungen eigentliche “Denkzeuge” sind: Mit Diagrammen kann operiert und im besten Fall aus bestehendem Wissen neue Erkenntnisse gewonnen werden. Für den korpuslinguistischen Zugang sind einige sog. diagrammatische Grundfiguren, also grundlegende Typen von Diagrammen, entscheidende Mittel, um den Untersuchungsgegenstand Sprache zu konstituieren, so z. B. die Liste, der Vektor und der Graph. Der Beitrag konzipiert diagrammatische Operationen als Grundbedingung der Korpuslinguistik und skizziert fünf diagrammatische Grund- guren. Zusätzlich wird an einem Beispiel, der Analyse von sog. Geokollokationen, gezeigt, wo der Wert explorativer visueller Korpusanalysen liegt.
 Bubenhofer, Noah / Dreesen, Philipp (2018): Linguistik als antifragile Disziplin? Optionen in der digitalen Transformation. In: Digital Classics Online Bd. 4, Nr. 1, S. 63–75, DOI: 10.11588/dco.2017.0.48493. Online (PDF)
BibTeX
Abstract
Bubenhofer, Noah / Dreesen, Philipp (2018): Linguistik als antifragile Disziplin? Optionen in der digitalen Transformation. In: Digital Classics Online Bd. 4, Nr. 1, S. 63–75, DOI: 10.11588/dco.2017.0.48493. Online (PDF)
BibTeX
Abstract
Die Digitalisierung führte zu massiven Umwälzungen in den Wissenschaften, insbesondere auch in den Geisteswissenschaften, was die Digital Humanities zeigen. Anhand der Linguistik diskutieren wir diese Veränderungen auf theoretischen, epistemologischen und methodologischen Ebenen, die insbesondere darin bestehen, dass Methoden maschineller Sprachverarbeitung zusehends alinguistisch sind. Es handelt sich also um Methoden, die sich nicht an linguistischen Theorien orientieren und keinen linguistischen Modellierungen von Sprache oder Sprachgebrauch folgen. Es bleibt dann zu fragen, wie eine wissenschaftliche Disziplin wie die Linguistik beschaffen sein muss, damit sie gegenüber solchen Umwälzungen nicht robust, sondern antifragil wird. Also wie sie reicher aus unvorhersehbaren Veränderungen herauskommen kann und sich gerade nicht primär in Abgrenzungs- und Abwehrkämpfe gegenüber solchen Umwälzungen ergehen muss.
Digitalization has led to massive changes in the sciences, especially in the humanities, as shown by the Digital Humanities. Using linguistics, we discuss these changes on theoretical, epistemological and methodological levels, which consist in particular in the fact that methods of machine language processing are increasingly alinguistic. These are methods that are not based on linguistic theories and do not follow linguistic modelling of language or language usage. It remains to ask how a scientific discipline such as linguistics must be structured so that it becomes antifragile rather than robust in the face of such revolutions. In other words, how it can get richer out of unforeseeable changes and does not primarily have to endure fights of demarcation and defence against such transformations.
 Bubenhofer, Noah (2018): Wenn „Linguistik“ in „Korpuslinguistik“ bedeutungslos wird. Vier Thesen zur Zukunft der Korpuslinguistik. In: Osnabrücker Beiträge zur Sprachtheorie (OBST), 92, S. 17-30. Preprint (PDF)
BibTeX
Abstract
Bubenhofer, Noah (2018): Wenn „Linguistik“ in „Korpuslinguistik“ bedeutungslos wird. Vier Thesen zur Zukunft der Korpuslinguistik. In: Osnabrücker Beiträge zur Sprachtheorie (OBST), 92, S. 17-30. Preprint (PDF)
BibTeX
Abstract
Ich möchte versuchen, die von den Herausgeber/innen dieses Bandes aufgeworfenen Fragen zu den theoretischen und methodologischen Problemen der Korpuslinguistik ganz grundsätzlich anzugehen. Mit einem Blick über die Grenzen unserer Disziplin hinaus, sehe ich nichts weniger als eine Entwicklung, die nicht nur die Korpuslinguistik, sondern auch die Linguistik insgesamt stark prägen wird. Ich glaube, dass linguistische Theorien und Kategorien Gefahr laufen, überall dort unbedeutend zu werden, wo es um die quantitative Analyse von Sprachgebrauch geht. Wenn diese Gefahr abgewendet werden kann, werden damit auch einige der theoretischen und methodologischen Probleme der Korpuslinguistik gelöst. Dies ist der Kern um vier Hypothesen herum, die ich im Folgenden skizzieren möchte – und die sicherlich überspitzt und provokativ formuliert sind.
 Bubenhofer, Noah/Rothenhäusler, Klaus (2018): „Die Aussicht ist grandios!“ – Korpuslinguistische Analyse narrativer Muster in Bergtourenberichten. In: Eller-Wildfeuer, Nicole/Rössler, Paul/Wildfeuer, Alfred (Hg.): Alpindeutsch. Einfluss und Verwendung des Deutschen im alpinen Raum. Regensburg (Sprachen im Kontakt), S. 39-60. Preprint (PDF)
BibTeX
Abstract
Bubenhofer, Noah/Rothenhäusler, Klaus (2018): „Die Aussicht ist grandios!“ – Korpuslinguistische Analyse narrativer Muster in Bergtourenberichten. In: Eller-Wildfeuer, Nicole/Rössler, Paul/Wildfeuer, Alfred (Hg.): Alpindeutsch. Einfluss und Verwendung des Deutschen im alpinen Raum. Regensburg (Sprachen im Kontakt), S. 39-60. Preprint (PDF)
BibTeX
Abstract
Eine Bergtour startet unten. Dann geht es hoch über Zwischenstationen auf den Gipfel. Danach steigt man wieder ab und landet wieder unten. Vielleicht startet man auch halb oben, nachdem man die erste Etappe schon am Vortag gemacht hat, vielleicht erklimmt man auch einen zweiten Gipfel. Die Anatomie einer Bergtour scheint prototypisch also ein Unten-Hoch-Gipfel-Runter-Unten zu sein, das einer topographisch erzwungenen Sequenz folgt.
Doch wie wird über solche Touren berichtet? Die Erzählung muss nicht der gegangenen Route entsprechen. So könnte man mit der Schilderung des Gipfelglücks beginnen, und erst dann vom anstrengenden Aufstieg erzählen. Man könnte den Abstieg komplett weglassen oder mit einem Halbsatz erledigen. Und welche narrativen Muster finden sich in solchen Berichten? Ist das Erreichen des Gipfels auch der narrative Höhepunkt der Geschichte? Oder ist die Schlüsselstelle davor viel spannender?
Ziel unserer kleinen Analyse ist, mit korpuslinguistischen Mitteln narrative Muster in Bergtourberichten zu entdecken, die wir als kommunikative Gattung im Sinne von Günthner und Knoblauch (1994) auffassen. Wir behelfen uns dabei mit mehreren Ansätzen, die zudem visuelle Analysemethoden nutzen, um die anfallenden zu analysierenden Daten überschaubar zu machen. Kern dieser Methoden ist unser korpuspragmatischer Ansatz, der mit Feilke (2000, S. 78) davon ausgeht, dass sich pragmatische Informationen im Gebrauchswert von sprachlichen Zeichen manifestieren. Diese pragmatischen Spuren werden an der Textoberfläche als Sprachgebrauchsmuster sichtbar und können deswegen mit korpuslinguistischen Methoden abgeschöpft werden (Bubenhofer, 2009; Bubenhofer/Scharloth, 2013; Scharloth/Bubenhofer, 2011). Wir können an dieser Stelle nicht ausführlich auf diese theoretischen Prämissen eingehen, die jedoch in einer Arbeit zu narrativen Mustern in Alltagsgeschichten Jugendlicher zum „Ersten Mal“ ausführlich dargelegt sind (Bubenhofer et al., 2013).
Bubenhofer, Noah (2018): Serialität der Singularität: Korpusanalyse narrativer Muster in Geburtsberichten. In: LiLi Zeitschrift für Literaturwissenschaft und Linguistik. DOI: 10.1007/s41244-018-0096-4. Online (HTML) Website zur Publikation
BibTeX
Abstract
In meinem Beitrag untersuche ich narrative Muster in vierzehntausend Berichten über Geburten, verfasst von Müttern in Internetforen. Ziel ist es dabei, typische Muster in diesen Geschichten zu finden, die jede für sich ein einmaliges Erlebnis erzählt, dabei jedoch auf Versatzstücke zurückgreifen. Dabei besteht das methodisches Interesse, mit Mitteln der Korpuslinguistik und der visuellen Analyse solche Muster zu finden. Analytisch stellt sich die Frage, welche gesellschaftlichen Vorstellungen darüber herrschen, wie Geburten erzählt werden sollen.
Bubenhofer, Noah (2018): Visual Linguistics: Plädoyer für ein neues Forschungsfeld. In: Bubenhofer, Noah/Kupietz, Marc (Hrsg.) (2018): Visualisierung sprachlicher Daten: Visual Linguistics – Praxis – Tools. Heidelberg: Heidelberg University Publishing. DOI: 10.17885/heiup.345.474. Online PDF/HTML
BibTeX
Abstract
Dialektkarten, Syntaxbäume, Kollokationsgraphen, Kommunikationsmodelle, Gesprächstranskripte, geclusterte Netzwerke: Die Linguistik ist geprägt von Diagrammen verschiedenster Art, um theoretische Modelle zu visualisieren, Daten zu explorieren oder Ergebnisse zu veranschaulichen. Damit nimmt die Disziplin keine Sonderstellung ein gegenüber anderen Disziplinen. Wissenschaftliche Visualisierungen sind überall ein wichtiges Mittel mit vielfältigen Funktionen.
Der Umgang mit Visualisierungen in der Linguistik ist aber, um es positiv zu formulieren, unbeschwert und vorwiegend kanonisch. Unbeschwert, weil weitgehend eine Reflexion darüber fehlt, welche semiotischen und hermeneutischen Eigenschaften und Effekte und welche wissenschaftsgeschichtlichen Implikationen Visualisierungen haben. Kanonisch, weil Visualisierungen in der Linguistik mehrheitlich als Mittel zum Zweck angesehen werden und deren Gebrauch deswegen bewährten Praktiken folgt, die aber das Experiment mit alternativen Visualisierungen scheut.
Im Folgenden möchte ich für ein Programm plädieren, das der Visualisierungspraxis in der Linguistik die Unbeschwertheit nimmt (dafür Erkenntnisse bietet, die für das Selbstverständnis des Fachs von Bedeutung sind) und die Gründe für die Wirkmächtigkeit von Visualisierungskanons untersucht und zum Experiment anstiftet. Dieses Programm nenne ich „Visual Linguistics“.
Die Eckpunkte des Programms ergeben sich aus drei Perspektiven, die mir fruchtbar für eine Analyse von Visualisierungspraktiken erscheinen und die ich im Folgenden näher beschreiben möchte:
- Die diagrammatische Perspektive: Was macht ein Diagramm zum Diagramm und welchen Status hat es in Forschungsprozessen?
- Die algorithmische Perspektive: Was ändert sich bei der Visualisierung von sprachlichen Phänomenen, wenn die Daten digital vorliegen und Visualisierungen computergeneriert sind?
- Die wissensgeschichtliche Perspektive: Warum ist das Diagramm als Drittes zwischen Sprache und wissenschaftlichem Arbeitsinstrument so wirkmächtig, dass es nicht nur Denkstile repräsentiert, sondern diese auch prägt?
Um es deutlich zu sagen: Für die jeweiligen Perspektiven gibt es einige Vorarbeiten aus der Philosophie und Semiotik (Diagrammatik), der Digital Humanities (Software Studies, Critical Code Studies), Medienwissenschaften (Computer als Medium) und der Wissenssoziologie und Wissenschaftsgeschichte. Die Verbindung dieser Erkenntnisse und die Anwendung auf die Linguistik ist jedoch nach wie vor ein Desiderat. Zudem haben sich in den letzten (wenigen) und werden sich in den kommenden Jahren durch die Masse digitaler Daten für die Geistes- und Kulturwissenschaften entscheidende Veränderungen ergeben, die mitbedacht werden müssen.
2017
Clematide, Simon/Meraner, Isabel/Bubenhofer, Noah/Volk, Martin: Lessons from a Massive Open Online Course (MOOC) on Natural Language Processing for Digital Humanities. In: Teaching NLP for Digital Humanities. Berlin 2017, S. 17–22. Online (PDF), BibTeX
Abstract
In this paper, we present the concept,
content and experience with an actively
running Massive Open Online Course
(MOOC) on Natural Language Processing
for Digital Humanities. This video-based
course is held in German, does not require
any programming skills, and serves as an
introduction to automatic text analysis. The
target audience is anyone who is interested
in applying basic language technology to
text corpora. It has a strong empirical focus on digital representations, tools and
corpus linguistics. The main goal thereby
is to grasp the fundamental terminology
and concepts of computational linguistics,
to understand the main problems and solutions, as well as to know about the performance and limitations of current methods.
Furthermore, manual annotation and data
visualization are introduced in this course.
 Bubenhofer, Noah (2017): Kollokationen, n-Gramme, Mehrworteinheiten. In: Roth, K./Wengeler, M./Ziem, A. (Hrsg.): Handbuch Sprache in Politik und Gesellschaft, Sprachwissen. Berlin / New York: De Gruyter. S. 69-93. Online (PDF) BibTeX
Abstract / Korrektur
Bubenhofer, Noah (2017): Kollokationen, n-Gramme, Mehrworteinheiten. In: Roth, K./Wengeler, M./Ziem, A. (Hrsg.): Handbuch Sprache in Politik und Gesellschaft, Sprachwissen. Berlin / New York: De Gruyter. S. 69-93. Online (PDF) BibTeX
Abstract / Korrektur
Der Beitrag beschreibt, wie die Berechnung von Kollokationen und Mehrworteinheiten in Textkorpora typische Sprachgebrauchsmuster freilegen kann. Zuerst werden in einer Gegenstandsbestimmung die verschiedenen Termini zur Bezeichnung von mehrgliedrigen Ausdrücken auf der sprachlichen Oberfläche diskutiert. Ein kurzer Forschungsüberblick nennt korpuslinguistische Arbeiten mit politolinguistischen Zielen, die Gebrauch von der Analyse solcher Mehrworteinheiten machen. Anschließend zeigt eine exemplarische Analyse von unterschiedlichen Typen von Mehrworteinheiten in parteispezifischen Teilkorpora der Wortprotokolle des Deutschen Bundestags die Einsatzmöglichkeiten.
Korrektur:
Die beiden Tabellen 2 und 3 im Beitrag haben falsche Spaltenbeschriftungen. Hier die korrigierten Versionen:
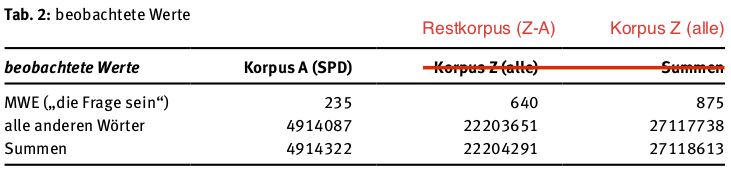

2016
 Bubenhofer, Noah/Rothenhäusler, Klaus (2016): „Korporatheken“: Die digitale und verdatete Bibliothek. In: 027.7 Zeitschrift für Bibliothekskultur / Journal for Library Culture 4 (2), DOI: 10.5281/ZENODO.4705307. Online (PDF) , BibTeX
Abstract
Bubenhofer, Noah/Rothenhäusler, Klaus (2016): „Korporatheken“: Die digitale und verdatete Bibliothek. In: 027.7 Zeitschrift für Bibliothekskultur / Journal for Library Culture 4 (2), DOI: 10.5281/ZENODO.4705307. Online (PDF) , BibTeX
Abstract
Mit dem digitalen Zeitalter ergeben sich für die Geisteswissenschaften neue methodologische Möglichkeiten, deren Wurzeln jedoch weit zurück reichen. Am Anfang steht der Index, der inzwischen mit viel weniger Aufwand als früher zum Volltextindex wird. Mit der anschließenden „Verdatung“ werden Sprachdaten verrechenbar und damit anders nutzbar. Welche Rolle können Bibliotheken in einer verdateten Welt spielen? Der folgende Beitrag betont nicht nur die technischen Möglichkeiten, sondern auch die Probleme, spezifisch aus geistes- und kulturwissenschaftlicher Sicht.
The digital era produces a whole range of new approaches for research in the humanities whose origins, however, can be traced far back. Their very source is the index, which can take the form of a full text index much easier than before. By turning text into data it becomes computationally tractable and can be used in novel ways. Which role can libraries play in a digitized world? This paper explores technical possibilities but it also points to problems specific for arts and social sciences.
 Bubenhofer, Noah/Scharloth, Joachim (2016): Kulturwissenschaftliche Orientierung in der Computer- und Korpuslinguistik. In: Sprache - Kultur - Kommunikation / Language - Culture - Communication Ein internationales Handbuch zu Linguistik als Kulturwissenschaft / An International Handbook of Linguistics as a Cultural Discipline. Bd. 43. Berlin, Boston: De Gruyter, S. 924–933. Preprint (PDF), BibTeX
Abstract
Bubenhofer, Noah/Scharloth, Joachim (2016): Kulturwissenschaftliche Orientierung in der Computer- und Korpuslinguistik. In: Sprache - Kultur - Kommunikation / Language - Culture - Communication Ein internationales Handbuch zu Linguistik als Kulturwissenschaft / An International Handbook of Linguistics as a Cultural Discipline. Bd. 43. Berlin, Boston: De Gruyter, S. 924–933. Preprint (PDF), BibTeX
Abstract
Das im Zuge der Digitalisierung gewachsene Interesse an empirischen, quantitativen Analysen von authentischen Sprachdaten hat auch jene Bereiche der Linguistik erfasst, die sozial- und kulturwissenschaftlich orientiert sind. Ihr Methodenrepertoire speist sich aus zwei Forschungstraditionen, die mehr und mehr zusammenwachsen: dem Information Retrieval und Text Mining einerseits und der Computer- und Korpuslinguistik andererseits. Digitalisierung bedeutet zählbar machen und so ist beiden Forschungsrichtungen gemeinsam, dass sie sprachliche Merkmale als Zahlen darstellen und mit Hilfe mathematischer Methoden untersuchen. Sprachliche Daten variieren im Gegensatz zu vielen anderen Datentypen in sehr vielen Dimensionen, sind daher auch eher niederfrequent verteilt und können auf unterschiedlichen Ebenen (Syntax, Lexik, Semantik etc.) analysiert werden. Texte sind Merkmalsvektoren, die die Distribution von Texteigenschaften repräsentieren. Eine Sammlung mehrerer Texte (Korpus) bildet eine Matrix.
Ansätze aus dem Bereich des Text Mining zielen häufig darauf, Modelle zu finden, die das Auffinden bestimmter Informationen in großen Textmengen ermöglichen. Sie lassen sich oft als Klassifikationsprobleme beschreiben, die mit Hilfe maschinellen Lernens gelöst werden. Dabei werden bereits klassifizierte Dokumente auf ihre linguistischen Eigenschaften hin analysiert (z.B. Distribution von Lemmata, Wortkombinationen, Buchstaben-n-Grammen etc.) und ein Klassifikator aus Merkmalsausprägungen bestimmt, der die vorher definierten Klassen möglichst gut trennt. Dieser Klassifikator kann dann dazu genutzt werden, künftige Klassifikationsaufgaben zu lösen, etwa um Korpora nach Textsorten zu sortierten oder Textstellen mit besonders hohem Informationsgehalt zu identifizieren. Hier wird deutlich, dass Text Mining eine starke Orientierung zur angewandten Forschung hat. Entsprechend ist die Frage, welche linguistischen Merkmale für die Klassifikation von besonderer Bedeutung sind und ob diese soziokulturelle Korrelate haben, von geringem Interesse.
Im Folgenden beschränken wir unsere Darstellung daher auf die sozial- und kulturwissenschaftlich interessierte Computer- und Korpuslinguistik. Hierfür werden wir zunächst die theoretischen Grundlagen (Kap. 2), dann unterschiedliche Forschungsparadigmen (Kap. 3) vorstellen; im Anschluss werden wir einen groben Überblick über grundlegende Typen von Analysekategorien geben (Kap. 4), ehe wir im letzten Kapitel die Bedeutung von Visualisierungen für die Analyse skizzieren (Kap.5).
Abegg, Andreas / Bubenhofer, Noah: "Empirische Linguistik im Recht – Empirical Linguistics in Law. Am Beispiel des Wandels des Staatsverständnisses im Sicherheitsrecht, öffentlichen Wirtschaftsrecht und Sozialrecht der Schweiz", Ancilla Iuris 1 (2016). Online (PDF) BibTeX
 Bubenhofer, Noah: "Drei Thesen zu Visualisierungspraktiken in den Digital Humanities", Rechtsgeschichte Legal History – Journal of the Max Planck Institute for European Legal History, 24, 2016, 351–355. Online BibTeX
Bubenhofer, Noah: "Drei Thesen zu Visualisierungspraktiken in den Digital Humanities", Rechtsgeschichte Legal History – Journal of the Max Planck Institute for European Legal History, 24, 2016, 351–355. Online BibTeX
2015
 Bubenhofer, Noah / Lange, Willi / Okamura, Saburo / Scharloth, Joachim: Wortschätze in Lehrbüchern für Deutsch als Fremdsprache: Möglichkeiten und Grenzen frequenzorientierter Ansätze. In: Kiesendahl, J. / Ott, C. (Hrsg.): Linguistik und Schulbuchforschung. Gegenstände – Methoden – Perspektiven, Eckert. Göttingen: V&R unipress, 2015, S. 85–110. Preprint (PDF)
BibTeX Abstract
Bubenhofer, Noah / Lange, Willi / Okamura, Saburo / Scharloth, Joachim: Wortschätze in Lehrbüchern für Deutsch als Fremdsprache: Möglichkeiten und Grenzen frequenzorientierter Ansätze. In: Kiesendahl, J. / Ott, C. (Hrsg.): Linguistik und Schulbuchforschung. Gegenstände – Methoden – Perspektiven, Eckert. Göttingen: V&R unipress, 2015, S. 85–110. Preprint (PDF)
BibTeX Abstract
Wortschatzaufbau ist neben der Vermittlung grammatikalischer und pragmatischer Kompetenz die zentrale Aufgabe von Lehrbüchern für Deutsch als Fremdsprache. Doch welcher Wortschatz soll vermittelt werden? Die Antwort klingt zwar einfach, bringt aber viele Probleme mit sich: Vermittelt werden sollten jene Wörter, die es den Lernenden ermöglichen, sich verstehend und verständigend in der Sprachgemeinschaft, die Trägerin der zu erlernenden Fremdsprache ist, zu bewegen. Das eigentliche Problem liegt jedoch darin, die Mittel, die dazu befähigen, sich mit den Angehörigen einer Sprachgemeinschaft zu verständigen, exakt zu benennen. Sie lassen sich nicht nur aus der kommunikativen Praxis der Sprachgemeinschaft ableiten, sondern hängen auch von den Interessen und Lebenslagen der Lernenden ab. Dennoch müssen Lehrbücher eine Auswahl aus der großen Anzahl an Lexemen treffen, die zum Wortschatz von Standardsprachen gehören. Das Kriterium, das dabei häufig zur Begründung dient, ist die Wahrscheinlichkeit, mit der ein Lerner bzw. eine Lernerin mit einem Wort in Kontakt kommt. Doch wie bestimmt man die Wahrscheinlichkeit, mit der man mit einem Wort einer Fremdsprache konfrontiert wird?
Der kommunikativ-pragmatische Ansatz geht von in Sprachgemeinschaften typischen kommunikativen Situationen und Sprechintentionen aus, denen dann die sprachlichen Mittel – und somit auch der Wortschatz – zugeordnet werden können. Für das Deutsche bilden die Bücher Zertifikat Deutsch als Fremdsprache (1972, Neubearbeitung 1992), Kontaktschwelle Deutsch (1980) und die deutsche Ausarbeitung des Gemeinsamen Europäischen Referenzrahmens für Sprachen in Profile (2005) Meilensteine des kommunikativ-pragmatischen Ansatzes. Insbesondere Profile scheint einen großen Einfluss auf die Lehrbücher zu haben. So plausibel dieser Ansatz auch klingt, so wenig empirisch fundiert ist er: Er beruht nicht auf einer Erhebung oder gar Quantifizierung des Sprachgebrauchs in typischen Alltagssituationen. Der Situationsbegriff ist theoretisch ebenso wenig hinreichend bestimmt wie das Alltagskonzept. Zudem sind die sprachlichen Selektionsverfahren intransparent.
Mit dem frequenzorientierten Ansatz wird das Ziel verfolgt, die Wahrscheinlichkeit zu bestimmen, mit der man mit einem Wort einer Fremdsprache konfrontiert wird. Zu diesem Zweck werden große Korpora auf das Auftreten von Lexemen hin untersucht. Für das Deutsche sind neben frühen Ausarbeitungen von Pfeffer (1970) und Rosengren (1972–1977) in jüngerer Zeit mit Jones/Tschirner (2006) und Tschirner (2008) neue frequenzbasierte Versuche der Bestimmung eines Grundwortschatzes getreten. In ihnen ist die Häufigkeit eines Wortes das Hauptkriterium der Selektion. Zwar geht dieser Ansatz empirisch vor, allerdings ist die Wahl des Korpus bzw. dessen Zusammenstellung und Umfang von entscheidender Bedeutung für das Ergebnis. Die vorhandenen Korpora freilich sind meist sehr selektiv im Hinblick auf die von ihnen abgedeckten Kommunikationsbereiche und bilden die gesprochene Sprache nur äußerst fragmentarisch ab. Zudem kann man am frequenzorientierten Ansatz kritisieren, dass Häufigkeit und Wichtigkeit von Lexemen verkürzend gleichgesetzt wird und dass wegen der starken Formbezogenheit Bedeutungsgesichtspunkte und die kommunikative Funktion von Wörtern generell vernachlässigt werden.
Gleichwohl haben frequenzorientierte Ansätze den Vorteil, dass sie überhaupt eine empirische Grundlage haben, ihre Ergebnisse folglich reproduzierbar sein müssen und somit die Möglichkeit eröffnen, intersubjektiv nachvollziehbare Maßstäbe in die Lehrwerkerstellung einzubringen.
In den folgenden Abschnitten wollen wir diskutieren, wie frequenzorientierte Ansätze für die Analyse von Lehrwerken nutzbar gemacht werden können. Wir beschränken uns hierbei auf die korpuslinguistisch recht einfach zu operationalisierenden Aspekte des Wortschatzes in Lehrwerken für Deutsch als Fremdsprache: die Distribution von Lexemen und den Wortschatzaufbau.
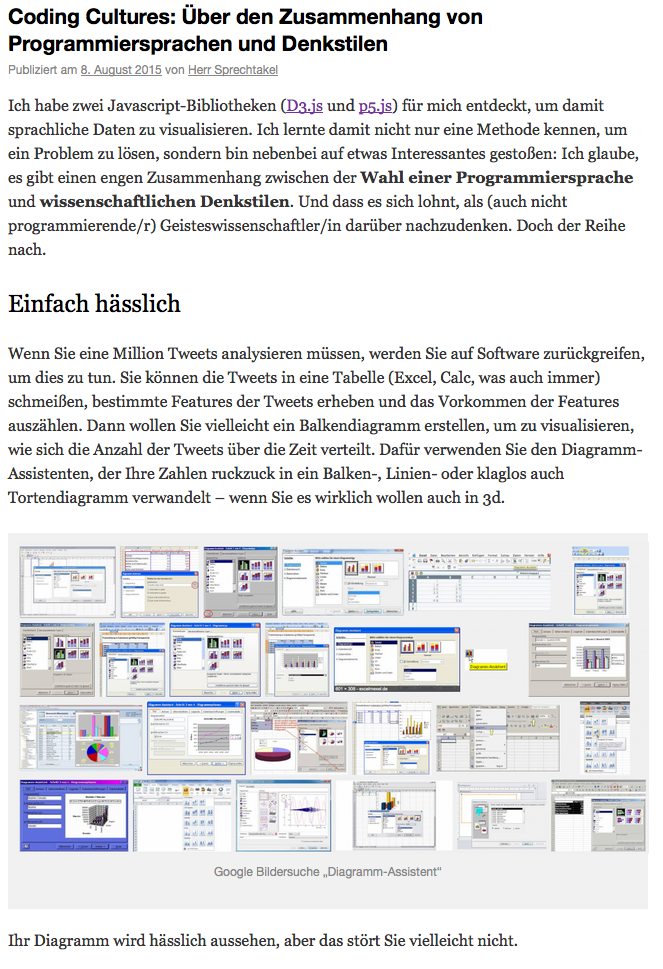 Bubenhofer, Noah (2015): Coding Cultures: Über den Zusammenhang von Programmiersprachen und Denkstilen. In: Sprechtakel, linguistische Notizen (Weblog). Online
Bubenhofer, Noah (2015): Coding Cultures: Über den Zusammenhang von Programmiersprachen und Denkstilen. In: Sprechtakel, linguistische Notizen (Weblog). Online
 Bubenhofer, Noah (2015): Muster aus korpuslinguistischer Sicht. In: Dürscheid, C./Schneider, J. G. (Hrsg.): Handbuch Satz – Äußerung – Schema, Sprachwissen. Berlin / New York: De Gruyter. S. 485-502, DOI: 10.1515/9783110296037-022. Preprint (PDF)
BibTeX Abstract
Bubenhofer, Noah (2015): Muster aus korpuslinguistischer Sicht. In: Dürscheid, C./Schneider, J. G. (Hrsg.): Handbuch Satz – Äußerung – Schema, Sprachwissen. Berlin / New York: De Gruyter. S. 485-502, DOI: 10.1515/9783110296037-022. Preprint (PDF)
BibTeX Abstract
Die Stärke korpuslinguistischer Methoden liegt darin, in großen Textmengen das serielle Auftreten eines bestimmten sprachlichen Phänomens zu entdecken. Es existiert deshalb vor dem Hintergrund des Firth’schen Kontextualismus eine lange Tradition, typische Kookkurrenzen von sprachlichen Einheiten statistisch zu berechnen, beispielsweise durch Kollokationsanalysen. Doch auch komplexere Phänomene, die über Wortpaare hinaus gehen und typische Kookkurrenzen von sprachlichen Einheiten unterschiedlicher Ebenen (Wortform, Grundform, morphosyntaktische Klasse etc.) umfassen, und die für bestimmte Textdaten typisch sind, können datengeleitet eruiert werden. Im Beitrag wird zunächst anhand von Beispielen die Palette der korpuslinguistischen Zugriffe auf Musterhaftigkeit in Texten dargestellt. Ausgehend von grundsätzlichen Gedanken zur korpuslinguistischen Perspektive auf Musterhaftigkeit werden die beiden wichtigen Paradigmen der Korpuslinguistik, korpusbasierte und datengeleitete Verfahren, herausgearbeitet. Auf der Grundlage dieser Überlegungen werden dann die wichtigsten Ansätze der Korpuslinguistik vorgestellt, die mit quantitativen Methoden Musterhaftigkeit in Textdaten testen oder entdecken.
 Bubenhofer, Noah/Scharloth, Joachim/Eugster, David (2015): Rhizome digital: Datengeleitete Methoden für alte und neue Fragestellungen in der Diskursanalyse. In: Zeitschrift für Diskursforschung, Sonderheft Diskurs, Interpretation, Hermeneutik, 1. Beiheft. S. 144-172. Preprint (PDF) BibTeX Abstract
Bubenhofer, Noah/Scharloth, Joachim/Eugster, David (2015): Rhizome digital: Datengeleitete Methoden für alte und neue Fragestellungen in der Diskursanalyse. In: Zeitschrift für Diskursforschung, Sonderheft Diskurs, Interpretation, Hermeneutik, 1. Beiheft. S. 144-172. Preprint (PDF) BibTeX Abstract
Mit dem „Data-Driven Turn“ ergeben sich in der digitalen Welt neue Chancen für die linguistische Diskursanalyse: Einerseits ist es oft ein Leichtes, große Textkorpora zusammenzustellen, um Analysen auf einer breiten empirischen Basis zu ermöglichen. Andererseits bedingen diese großen Datenmengen neue Untersuchungsmethoden; die Anwendung von Erkenntnissen der Korpus- und Computerlinguistik ermöglichen datengeleitete Zugänge, mit denen auch neue Forschungsfragen angegangen werden können. Wir demonstrieren dies anhand datengeleiteter Analysen zu zeitgeschichtlichen Umbrüchen in SPIEGEL und ZEIT.
The „data driven turn“ as a result of the digital world enables new approaches to linguistic discourse analysis: On the one hand, it is often much easier to build big text corpora for analyses on a broader empirical basis. On the other hand, using big data demands new methods to access it. The use of state-of-the-art techniques of corpus- and computational linguistics enables data-driven approaches, which allow also pursuing new research questions. An analysis of cultural upheavals in Germany after WW II in the newspapers SPIEGEL and ZEIT illustrates these possibilities.
Bubenhofer, Noah/Scharloth, Joachim (2015): Maschinelle Textanalyse im Zeichen von Big Data und Data-driven Turn – Überblick und Desiderate. In: Zeitschrift für Germanistische Linguistik. 43/1, S. 1-26, DOI: 10.1515/zgl-2015-0001. Preprint (PDF)
BibTeX
 Hein, Katrin/Bubenhofer, Noah (2015): Korpuslinguistik konstruktionsgrammatisch. Diskursspezifische n-Gramme zwischen statistischer Signifikanz und semantisch-pragmatischem Mehrwert. In: Lasch, A./Ziem, A. (Hrsg.): Konstruktionsgrammatik IV: Konstruktionen als soziale Konventionen und kognitive Routinen. Tübingen: Stauffenburg, 2015, S. 179–206. Preprint (PDF).
Hein, Katrin/Bubenhofer, Noah (2015): Korpuslinguistik konstruktionsgrammatisch. Diskursspezifische n-Gramme zwischen statistischer Signifikanz und semantisch-pragmatischem Mehrwert. In: Lasch, A./Ziem, A. (Hrsg.): Konstruktionsgrammatik IV: Konstruktionen als soziale Konventionen und kognitive Routinen. Tübingen: Stauffenburg, 2015, S. 179–206. Preprint (PDF).
2014
 Bubenhofer, Noah/Hansen-Morath, Sandra/Konopka, Marek: Korpusbasierte Exploration der Variation der nominalen Genitivmarkierung. In: Zeitschrift für germanistische Linguistik Bd. 42 (2014), Nr. 3, S. 379–419, DOI: 10.1515/zgl-2014-0024. Online
Bubenhofer, Noah/Hansen-Morath, Sandra/Konopka, Marek: Korpusbasierte Exploration der Variation der nominalen Genitivmarkierung. In: Zeitschrift für germanistische Linguistik Bd. 42 (2014), Nr. 3, S. 379–419, DOI: 10.1515/zgl-2014-0024. Online
 Bubenhofer, Noah/Scharloth, Joachim (2014): Sprachthematisierungen: Ein korpuslinguistisch-frequenzorientierter Zugang. In: Aptum. Zeitschrift für Sprachkritik und Sprachkultur (2014), Nr. 2, S. 140–154, DOI: 10.46771/9783967691474_4.
Bubenhofer, Noah/Scharloth, Joachim (2014): Sprachthematisierungen: Ein korpuslinguistisch-frequenzorientierter Zugang. In: Aptum. Zeitschrift für Sprachkritik und Sprachkultur (2014), Nr. 2, S. 140–154, DOI: 10.46771/9783967691474_4.
 Bubenhofer, Noah (2014): Geokollokationen – Diskurse zu Orten: Visuelle Korpusanalyse. In: Mitteilungen des Deutschen Germanistenverbandes 1/2014: Korpora in der Linguistik – Perspektiven und Positionen zu Daten und Datenerhebung. S. 45-59, DOI: 10.14220/mdge.2014.61.1.45. Siehe hier für weiterführende Informationen und Zusatzmaterial. Preprint (PDF).
Bubenhofer, Noah (2014): Geokollokationen – Diskurse zu Orten: Visuelle Korpusanalyse. In: Mitteilungen des Deutschen Germanistenverbandes 1/2014: Korpora in der Linguistik – Perspektiven und Positionen zu Daten und Datenerhebung. S. 45-59, DOI: 10.14220/mdge.2014.61.1.45. Siehe hier für weiterführende Informationen und Zusatzmaterial. Preprint (PDF).
 Bubenhofer, Noah/Scheurer, Patricia (2014): Warum man in die Berge geht. Das kommunikative Muster "Begründen" in alpinistischen Texten. In: Hauser, S./Kleinberger, U./Roth, K. S. (Hrsg.): Musterwandel – Sortenwandel. Aktuelle Tendenzen der diachronen Text(sorten)linguistik, Sprache in Kommunikation und Medien. Bern, Berlin etc.: Peter Lang, 2014. Preprint (PDF).
Bubenhofer, Noah/Scheurer, Patricia (2014): Warum man in die Berge geht. Das kommunikative Muster "Begründen" in alpinistischen Texten. In: Hauser, S./Kleinberger, U./Roth, K. S. (Hrsg.): Musterwandel – Sortenwandel. Aktuelle Tendenzen der diachronen Text(sorten)linguistik, Sprache in Kommunikation und Medien. Bern, Berlin etc.: Peter Lang, 2014. Preprint (PDF).
 Bubenhofer, Noah/Scharloth, Joachim (2014): "Korpuspragmatische Methoden für kulturanalytische Fragestellungen". In: Benitt, Nora et al. (Hrsg.): Kommunikation – Korpus – Kultur. Ansätze und Konzepte einer kulturwissenschaftlichen Linguistik. Giessen Contributions to the Study of Culture, Trier: Wvt Wissenschaftlicher Verlag. S. 47-66. Preprint (PDF) Code auf GitHub (lexiconclustering).
Bubenhofer, Noah/Scharloth, Joachim (2014): "Korpuspragmatische Methoden für kulturanalytische Fragestellungen". In: Benitt, Nora et al. (Hrsg.): Kommunikation – Korpus – Kultur. Ansätze und Konzepte einer kulturwissenschaftlichen Linguistik. Giessen Contributions to the Study of Culture, Trier: Wvt Wissenschaftlicher Verlag. S. 47-66. Preprint (PDF) Code auf GitHub (lexiconclustering).
 Ebling, Sarah/Scharloth, Joachim/Dussa, Tobias/Bubenhofer, Noah (2014): Gibt es eine Sprache des politischen Extremismus? In: Frank Liedtke (Hrsg.): Die da oben. Texte, Medien, Partizipation. Bremen: Hempen. S. 43-68.
Ebling, Sarah/Scharloth, Joachim/Dussa, Tobias/Bubenhofer, Noah (2014): Gibt es eine Sprache des politischen Extremismus? In: Frank Liedtke (Hrsg.): Die da oben. Texte, Medien, Partizipation. Bremen: Hempen. S. 43-68.
2013
 Bubenhofer, Noah/Müller, Nicole/Scharloth, Joachim (2013): Narrative Muster und Diskursanalyse: Ein datengeleiteter Ansatz. In: Zeitschrift für Semiotik, Methoden der Diskursanalyse Bd. 35, Nr. 3-4, S. 419–444. BibTeX Abstract
Bubenhofer, Noah/Müller, Nicole/Scharloth, Joachim (2013): Narrative Muster und Diskursanalyse: Ein datengeleiteter Ansatz. In: Zeitschrift für Semiotik, Methoden der Diskursanalyse Bd. 35, Nr. 3-4, S. 419–444. BibTeX Abstract
Narratives are pre-existent socially accepted forms of interpretation, which de-lineate and confine the interpretation strategies in individual texts. Even though narratives shape the ‘sayable’ in a Foucaultian sense, they have so far been widely neglected by linguistic discourse analysis. In this paper we discuss data-driven methods in the analysis of narratives. Using 3376 stories of the first sexual encounter as an example, we propose using hierarchical ngram-collocation-graphs as a means of visualizing the complex co-occurrence-structure that forms narratives on the textual surface.
Zusammenfassung. Narrative sind sozial akzeptierte Interpretationsmuster, die unsere Wahrnehmung und Darstellung von Zusammenhängen ermöglichen und gleichzeitig begrenzen. Obwohl sie eine wichtige Funktion bei der Konstruktion der Grenzen des Sagbaren im Foucaultschen Sinn haben, wurden sie von der linguistischen Diskursanalyse bislang weitgehend vernachlässigt. Am Beispiel von 3376 Geschichten vom „Ersten Mal“ illustrieren wir in diesem Aufsatz methodische Ansätze zur Rekonstruktion von Narrativen. Das von uns vorgeschlagene Verfahren zur Analyse und Visualisierung von Narrativen ist die datengeleitete Berechnung von hierarchischen n-Gramm-Kollokationsgraphen.
Bubenhofer, Noah (2013): Mediale Skandalisierung korpuslinguistisch. Ein empirisch-linguistischer Blick auf die Berichterstattung zur "Wulff-Affäre". In: Linguistische Methoden im Fokus: Eine Auswahl projektbasierter Beispiele. Linguistik online 61/4, http://www.linguistik-online.de/61_13/. Online
 Scharloth, Joachim/Eugster, David/Bubenhofer, Noah (2013): Das Wuchern der Rhizome. Linguistische Diskursanalyse und Data-driven Turn. In: Busse, Dietrich/Teubert, Wolfgang (Hrsg.): Linguistische Diskursanalyse. Neue Perspektiven. Wiesbaden: Springer VS. S. 345-380. Zusammenfassung und Preprint (PDF).
Scharloth, Joachim/Eugster, David/Bubenhofer, Noah (2013): Das Wuchern der Rhizome. Linguistische Diskursanalyse und Data-driven Turn. In: Busse, Dietrich/Teubert, Wolfgang (Hrsg.): Linguistische Diskursanalyse. Neue Perspektiven. Wiesbaden: Springer VS. S. 345-380. Zusammenfassung und Preprint (PDF).
 Bubenhofer, Noah/Scharloth, Joachim (2013): Korpuslinguistische Diskursanalyse: Der Nutzen empirisch-quantitativer Verfahren. In: Warnke, Ingo H./Meinhof, Ulrike/Reisigl, Martin (Hrsg.): Diskurslinguistik im Spannungsfeld von Deskription und Kritik. Berlin: Akademie-Verlag. S. 147-168. Preprint (PDF).
Bubenhofer, Noah/Scharloth, Joachim (2013): Korpuslinguistische Diskursanalyse: Der Nutzen empirisch-quantitativer Verfahren. In: Warnke, Ingo H./Meinhof, Ulrike/Reisigl, Martin (Hrsg.): Diskurslinguistik im Spannungsfeld von Deskription und Kritik. Berlin: Akademie-Verlag. S. 147-168. Preprint (PDF).
 Bubenhofer, Noah (2013): Quantitativ informierte qualitative Diskursanalyse. Korpuslinguistische Zugänge zu Einzeltexten und Serien. In: Roth, Kersten Sven/Spiegel, Carmen (Hrsg.): Angewandte Diskurslinguistik. Felder, Probleme, Perspektiven. Berlin: Akademie-Verlag. S. 109-134. Preprint (PDF).
Bubenhofer, Noah (2013): Quantitativ informierte qualitative Diskursanalyse. Korpuslinguistische Zugänge zu Einzeltexten und Serien. In: Roth, Kersten Sven/Spiegel, Carmen (Hrsg.): Angewandte Diskurslinguistik. Felder, Probleme, Perspektiven. Berlin: Akademie-Verlag. S. 109-134. Preprint (PDF).
2012
Bubenhofer, Noah (2012): Lehrwerke und Referenzwortschätze. Der Nutzen frequenzbasierter Grundwortschätze. In: Okamura, Saburo/Lange, Willi/Scharloth, Joachim (Hrsg.): Grundwortschatz Deutsch: lexiko-grafische und fremdsprachendidaktische Perspektiven, Studienreihe der Japanischen Gesellschaft für Germanistik (SrJGG) 088, Tokyo, S. 13-27.
 Schröter, Juliane/Linke, Angelika/Bubenhofer, Noah (2012): "Ich als Linguist" – Eine empirische Studie zur Einschätzung und Verwendung des generischen Maskulinums. In: Günthner, Susanne/Hüpper, Dagmar/Spieß, Constanze (Hrsg.): Genderlinguistik. Berlin, Boston: de Gruyter, S. 359–380.
Schröter, Juliane/Linke, Angelika/Bubenhofer, Noah (2012): "Ich als Linguist" – Eine empirische Studie zur Einschätzung und Verwendung des generischen Maskulinums. In: Günthner, Susanne/Hüpper, Dagmar/Spieß, Constanze (Hrsg.): Genderlinguistik. Berlin, Boston: de Gruyter, S. 359–380.
 Bubenhofer, Noah/Scharloth, Joachim (2012): „Stil als Kategorie der soziopragmatischen Sprachgeschichte: Korpusgeleitete Zugänge zur Sprache der 68er-Bewegung“. In: Maitz, Péter (Hrsg.): Historische Sprachwissenschaft. Erkenntnisinteressen, Grundlagenprobleme, Desiderate. Studia Linguistica Germanica 110, Berlin/Boston: de Gruyter, S. 227–261.
Bubenhofer, Noah/Scharloth, Joachim (2012): „Stil als Kategorie der soziopragmatischen Sprachgeschichte: Korpusgeleitete Zugänge zur Sprache der 68er-Bewegung“. In: Maitz, Péter (Hrsg.): Historische Sprachwissenschaft. Erkenntnisinteressen, Grundlagenprobleme, Desiderate. Studia Linguistica Germanica 110, Berlin/Boston: de Gruyter, S. 227–261.
Bubenhofer, Noah/Schröter, Juliane (2012): „Die Alpen. Sprachgebrauchsgeschichte – Korpuslinguistik – Kulturanalye“. In: Maitz, Péter (Hrsg.): Historische Sprachwissenschaft. Erkenntnisinteressen, Grundlagenprobleme, Desiderate. Studia Linguistica Germanica 110, Berlin/Boston: de Gruyter, S. 263–287.
 Scharloth, Joachim/Bubenhofer, Noah/Rothenhäusler, Klaus (2012): "Andersschreiben aus korpuslinguistischer Perspektive: Datengeleitete Zugänge zum Stil". In: Schuster, Britt-Marie/Tophinke, Doris (Hrsg.): Andersschreiben: Formen, Funktionen, Traditionen, Berlin: Schmidt, S. 157–178.
Scharloth, Joachim/Bubenhofer, Noah/Rothenhäusler, Klaus (2012): "Andersschreiben aus korpuslinguistischer Perspektive: Datengeleitete Zugänge zum Stil". In: Schuster, Britt-Marie/Tophinke, Doris (Hrsg.): Andersschreiben: Formen, Funktionen, Traditionen, Berlin: Schmidt, S. 157–178.
 Bubenhofer, Noah/Hein, Katrin/Brinckmann, Caren (2012): Maschinelles Lernen zur Vorhersage von Fugenelementen in nominalen Komposita. grammis 2.0: Korpusgrammatik, Insitut für Deutsche Sprache, Mannheim. Online
Bubenhofer, Noah/Hein, Katrin/Brinckmann, Caren (2012): Maschinelles Lernen zur Vorhersage von Fugenelementen in nominalen Komposita. grammis 2.0: Korpusgrammatik, Insitut für Deutsche Sprache, Mannheim. Online
Bubenhofer, Noah (2012): Statistische Methoden für korpusgrammatische Analysen. grammis 2.0: Korpusgrammatik, Insitut für Deutsche Sprache, Mannheim. Online
 Bubenhofer, Noah/Spieß, Constanze (2012): Zur grammatischen Oberflächenstruktur von Kommentaren. Eine korpuslinguistische Analyse typischer Sprachgebrauchsmuster im kontrastiven Vergleich. In: Grösslinger,
Christian/Held, Gudrun/Stöckl, Hartmut (Hrsg.): Pressetextsorten jenseits
der "News": Medienlinguistische Perspektiven auf journalistische Kreativität. Frankfurt: Peter Lang (=
Sprache im Kontext 38), S. 87-105. Preprint PDF
Bubenhofer, Noah/Spieß, Constanze (2012): Zur grammatischen Oberflächenstruktur von Kommentaren. Eine korpuslinguistische Analyse typischer Sprachgebrauchsmuster im kontrastiven Vergleich. In: Grösslinger,
Christian/Held, Gudrun/Stöckl, Hartmut (Hrsg.): Pressetextsorten jenseits
der "News": Medienlinguistische Perspektiven auf journalistische Kreativität. Frankfurt: Peter Lang (=
Sprache im Kontext 38), S. 87-105. Preprint PDF
 Scharloth, Joachim/Bubenhofer, Noah (2012): Datengeleitete Korpuspragmatik:
Korpusvergleich als Methode der Stilanalyse. In: Felder, Ekkehard/Müller, Marcus/Vogel, Friedemann (Hgg.): Korpuspragmatik. Thematische Korpora als Basis diskurslinguistischer Analysen. Berlin, New York: de Gruyter, S. 195-230. Preprint PDF
Scharloth, Joachim/Bubenhofer, Noah (2012): Datengeleitete Korpuspragmatik:
Korpusvergleich als Methode der Stilanalyse. In: Felder, Ekkehard/Müller, Marcus/Vogel, Friedemann (Hgg.): Korpuspragmatik. Thematische Korpora als Basis diskurslinguistischer Analysen. Berlin, New York: de Gruyter, S. 195-230. Preprint PDF
2011
Bubenhofer, Noah/Scharloth, Joachim (2011): Korpuspragmatische Analysen alpinistischer Literatur. In: Elmiger, Daniel/Kamber, Alain (Hrsg.): La linguistique de corpus – de l’analyse quantitative à l’interpretation qualitative / Korpuslinguistik – von der quantitativen Analyse zur qualitativen Interpretatino, Travaux neuchâtelois de linguistique 55, Neuchâtel: Institut des sciences du langage et de la communication, S. 241–259. Preprint (PDF).
Bubenhofer, Noah/Haupt, Stefanie/Schwinn, Horst (2011): A Comparable Corpus of the Wikipedia: From Wiki Syntax to POS Tagged XML. Hamburg Working Paper in Multilingualism, 96 B.
Bubenhofer Noah (2011): "Korpuslinguistik in der linguistischen Lehre: Erfolge und Misserfolge", JLCL 26/1, S. 141-156. Online (PDF)
Bubenhofer, Noah/Lange, Willi/Okamura, Saburo/Scharloth, Joachim (2011): Welcher Wortschatz? Korpuslinguistische Untersuchungen zur Wortschatzselektion japanischer Deutschlehrbücher für Anfänger. In: Doitsugo Kyoiku - Deutschunterricht in Japan 16, S. 43-60. Download PDF
 Brinckmann, Caren/Bubenhofer, Noah (2011): "Sagen kann man's schon, nur schreiben tut man's selten" – Die tun-Periphrase. In: Grammatik in Fragen und Antworten, Online-Publikation. Mannheim, Institut für Deutsche Sprache. Online
Brinckmann, Caren/Bubenhofer, Noah (2011): "Sagen kann man's schon, nur schreiben tut man's selten" – Die tun-Periphrase. In: Grammatik in Fragen und Antworten, Online-Publikation. Mannheim, Institut für Deutsche Sprache. Online
2010
Scharloth, Joachim/Gerber, Christian/Glättli, Balthasar/Studer, Michel/Bubenhofer, Noah/Ebling, Sarah/
Vola, Saskia (2010): Die Schweiz in der Krise: Korpuspragmatische Untersuchungen zur sprachlichen Konstruktion und Diffusion von Krisensemantiken. In: Aptum. Zeitschrift für Sprachkritik und Sprachkultur, 6/02, S. 99-120.
Bubenhofer, Noah/Ptashnyk, Stefaniya (2010): Korpora, Datenbanken und das Web:
State of the Art computergestützter Forschung in der Phraseologie und Lexikographie. In: Ptashnyk, Stefaniya/Hallsteinsdóttir, Erla/Bubenhofer, Noah (Hrsg.): "Korpora, Web und Datenbanken. Computergestützte Methoden in der modernen
Phraseologie und Lexikographie/Corpora, Web and Databases. Computer-Based Methods in Modern Phraseology
and Lexicography." Phraseologie & Parömiologie, Hohengehren, Schneider Verlag. S. 7–20. Download PDF
Volk, Martin/Bubenhofer, Noah/Althaus, Adrian/Bangerter, Maya/Furrer, Lenz/Ruef, Beni (2010):
Challenges in Building a Multilingual Alpine Heritage Corpus. In: Seventh International Conference on Language Resources and Evaluation (LREC), Malta, 19
May 2010 - 21 May 2010, p. 1653-1659. Download PDF
 Bubenhofer, Noah/Scharloth, Joachim (2010): Kontext korpuslinguistisch: Die induktive Berechnung von Sprachgebrauchsmustern in großen Textkorpora. In: Kontexte und Texte. Studien zu soziokulturellen Konstellationen literalen Handelns, hg. v. Peter Klotz, Paul R. Portmann-Tselikas u. Georg Weidacher, Tübingen: Narr. S. 85-108. Download PDF
Bubenhofer, Noah/Scharloth, Joachim (2010): Kontext korpuslinguistisch: Die induktive Berechnung von Sprachgebrauchsmustern in großen Textkorpora. In: Kontexte und Texte. Studien zu soziokulturellen Konstellationen literalen Handelns, hg. v. Peter Klotz, Paul R. Portmann-Tselikas u. Georg Weidacher, Tübingen: Narr. S. 85-108. Download PDF
2009
Bubenhofer, Noah/Dussa, Tobias/Ebling, Sarah/Klimke, Martin/Rothenhäusler, Klaus/Scharloth, Joachim/Tamekue, Suarès/Vola, Saskia (Forschergruppe semtracks) (2009): "So etwas wie eine Botschaft". Korpuslinguistische Analysen der Bundestagswahl 2009. Sprachreport 4/2009, Mannheim: Institut für Deutsche Sprache. S. 2–10. Download PDF
Volk, Martin/Bubenhofer, Noah/Althaus, Adrian/Bangerter, Maya (2009): Classifying Named Entities in an Alpine Heritage Corpus. Künstliche Intelligenz, 4, S. 40–43. Download PDF
Bubenhofer, Noah/Haaf, Susanne/Jourdain, Céline/Scharloth, Joachim/Schnoz, Monika/Stutz, Ursula (2009): XML-Technologien als Grundlage dynamischer Textpräsentation. Die digitale Quellenedition "Der Zürcher Sommer 1968". In: Braungart, Georg/Gendolla, Peter/Jannidis, Fotis (Hrsg.): Jahrbuch für Computerphilologie 9, Paderborn. Online
2008
 Bubenhofer, Noah (2008): "Es liegt in der Natur der Sache…". Korpuslinguistische Untersuchungen zu Kollokationen in Argumentationsfiguren. In: Mellado Blanco, Carmen (Hrsg.): Beiträge zur Phraseologie aus textueller Sicht. (PHILOLOGIA - Sprachwissenschaftliche Forschungsergebnisse 112 ), Hamburg, Kovac. S. 53-72. Download PDF
Bubenhofer, Noah (2008): "Es liegt in der Natur der Sache…". Korpuslinguistische Untersuchungen zu Kollokationen in Argumentationsfiguren. In: Mellado Blanco, Carmen (Hrsg.): Beiträge zur Phraseologie aus textueller Sicht. (PHILOLOGIA - Sprachwissenschaftliche Forschungsergebnisse 112 ), Hamburg, Kovac. S. 53-72. Download PDF
 Bubenhofer, Noah (2008): Diskurse berechnen? Wege zu einer korpuslinguistischen Diskursanalyse. In: Spitzmüller, Jürgen/Warnke, Ingo (Hrsg.): Methoden der Diskurslinguistik. Sprachwissenschaftliche Zugänge zur transtextuellen Ebene. Berlin/New York, de Gruyter. S. 407-434. Download PDF
Bubenhofer, Noah (2008): Diskurse berechnen? Wege zu einer korpuslinguistischen Diskursanalyse. In: Spitzmüller, Jürgen/Warnke, Ingo (Hrsg.): Methoden der Diskurslinguistik. Sprachwissenschaftliche Zugänge zur transtextuellen Ebene. Berlin/New York, de Gruyter. S. 407-434. Download PDF
2005
Bertschi, Stefan/Bubenhofer, Noah (2005): Linguistic Learning: A New Conceptual Focus in Knowledge Visualization. In: IEEE Computer Society (Hrsg.): Proceedings of the Ninth International Conference on Information Visualisation (IV'05). IV Washington, DC, USA. S. 383-389. Download PDF
Rezensionen / Reviews
Bubenhofer, Noah: Rezension von: Iva Kratochvílová/Norbert Richard Wolf (Hg.): Kompendium Korpuslinguistik. Eine Bestandesaufnahme aus deutsch-tschechischer Perspektive. Heidelberg: Winter 2010. In: Zeitschrift für Dialektologie und Linguistik LXXVIII (3), 2011. S. 353–355.
Bubenhofer, Noah: Rezension von: Lothar Lemnitzer: "Von Aldianer bis Zauselquote." Neue deutsche Wörter - Wo sie herkommen und wofür wir sie brauchen. Tübingen: Narr 2007. Zeitschrift für Rezensionen zur germanistischen Sprachwissenschaft 1, 2009. S. 70–73.
Bubenhofer, Noah: Kurzrezension von: Jürgen Spitzmüller: Metasprachdiskurse. Einstellungen zu Anglizismen und ihre wissenschaftliche Rezeption. Berlin: De Gruyter 2005 (Linguistik Impulse & Tendenzen 11). 476 Seiten. Zeitschrift für Sprachwissenschaft 26, 2007. S. 132–134.
Varia
 Bubenhofer, Noah (2006-): Sprechtakel. Linguistische Notizen. Weblog.
Bubenhofer, Noah (2006-): Sprechtakel. Linguistische Notizen. Weblog.
 Donalies, Elke (2011): Tagtraum, Tageslicht, Tagedieb. Ein korpuslinguistisches Experiment zu variierenden Wortformen und Fugenelementen in zusammengesetzten Substantiven. Mit einem Exkurs und zahlreichen Statistiken von Noah Bubenhofer. Mannheim: Institut für Deutsche Sprache (=amades 42).
Donalies, Elke (2011): Tagtraum, Tageslicht, Tagedieb. Ein korpuslinguistisches Experiment zu variierenden Wortformen und Fugenelementen in zusammengesetzten Substantiven. Mit einem Exkurs und zahlreichen Statistiken von Noah Bubenhofer. Mannheim: Institut für Deutsche Sprache (=amades 42).
Bubenhofer, Noah/Volk, Martin/Althaus, Adrian/Jitca, Magdalena/Bangerter, Maya/Sennrich, Rico (Hrsg.): Text+Berg-Korpus (Release 145). Digitale Edition des Jahrbuch des SAC 1864-1923 und Die Alpen 1925-2009. Institut für Computerlinguistik, Universität Zürich, 2011.
Bubenhofer, Noah/Volk, Martin/Althaus, Adrian/Ruef, Beni (Hrsg.): Text+Berg-Korpus (Release 100), XML-Format, Digitale Edition des "Jahrbuch des SAC" 1864–1923 und "Die Alpen" 1925–1964, Universität Zürich, 2009.
Bubenhofer, Noah/Klimke, Martin/Scharloth, Joachim: Bundestagswahl ‘09. Eine Semantische Matrixanalyse. Online-Publikation, semtracks Political Tracker, 2009. http://www.semtracks.org/web/politicaltracker/bundestagswahl/
 Der Zürcher Sommer 1968. Herausgegeben von Joachim Scharloth und Angelika Linke, unter Mitarbeit von Noah Bubenhofer, Susanne Haaf, Céline Jourdain, Monika Schnoz, Ursula Stutz, Peter Zaugg und Angela Zimmermann. Zürich 2008.
Der Zürcher Sommer 1968. Herausgegeben von Joachim Scharloth und Angelika Linke, unter Mitarbeit von Noah Bubenhofer, Susanne Haaf, Céline Jourdain, Monika Schnoz, Ursula Stutz, Peter Zaugg und Angela Zimmermann. Zürich 2008.
Bubenhofer, Noah/Klimke, Martin/Scharloth, Joachim: U.S. Presidential Campaign '08: A Semantic Matrix Analysis. Online Publication, semtracks Political Tracker, 2008. http://www.semtracks.org/web/politicaltracker/
Bubenhofer, Noah/Klimke, Martin/Scharloth, Joachim (2008): The Word War: "Yes, He Did". How Obama won the (rhetorical) battle for the White House. International Relations and Security Network, ISN ETH Zurich.
Bubenhofer, Noah/Klimke, Martin/Scharloth, Joachim (2008): Die "Wort-Wahl": Barack Obama und John McCains rhetorischer Kampf ums Weiße Haus. suite101.de.