
Was „zeigt“ sich, wenn eine Maschine einen Text „liest“, also sequenziell Wort für Wort abarbeitet? Eher für didaktische Zwecke habe ich eine kleine Spielerei versucht (und dabei mit P5.js experimentiert):
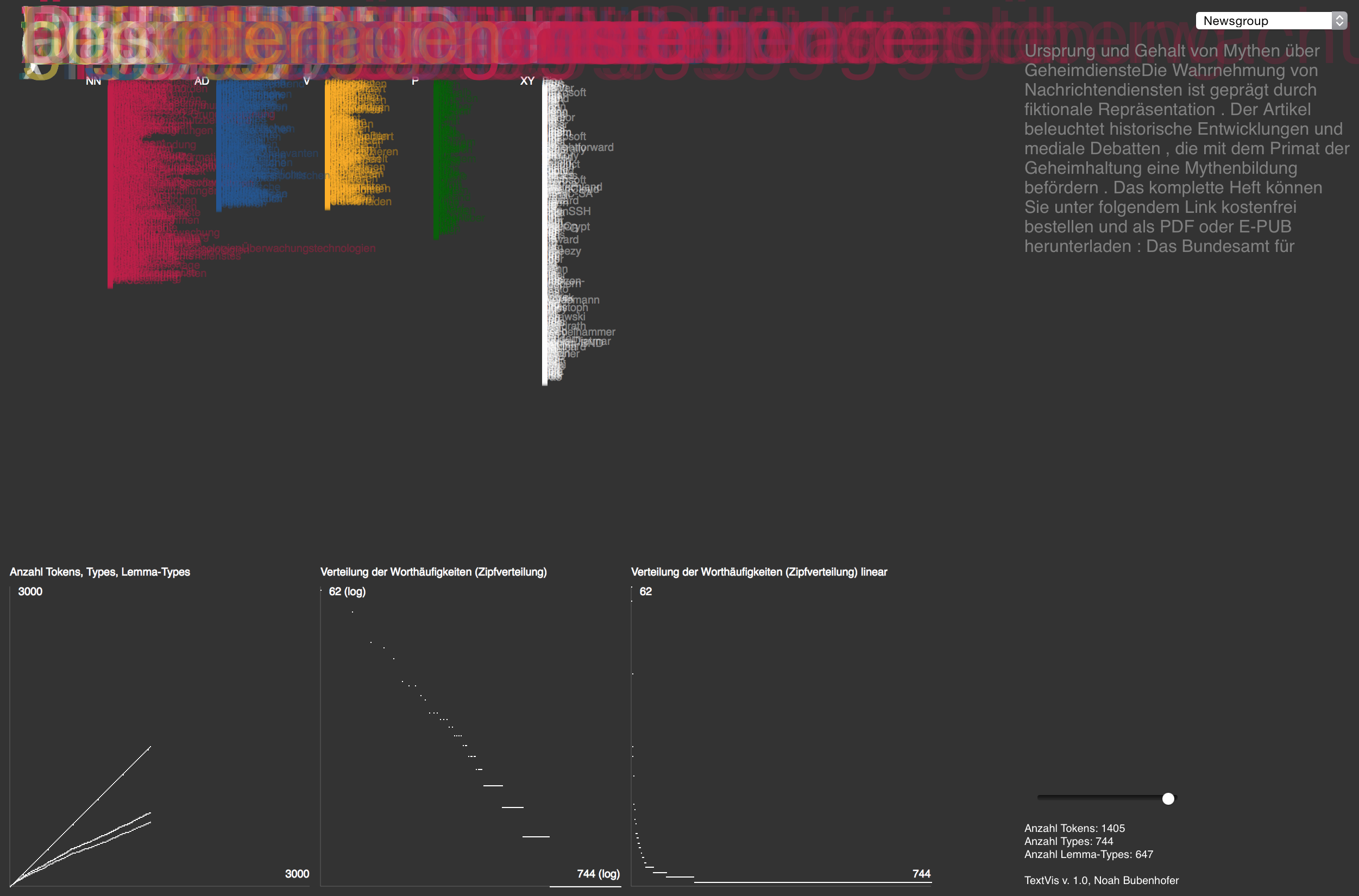
Screenshot TextVis 1.0
Was „zeigt“ sich, wenn eine Maschine einen Text „liest“, also sequenziell Wort für Wort abarbeitet? Eher für didaktische Zwecke habe ich eine kleine Spielerei versucht (und dabei mit P5.js experimentiert):
Screenshot TextVis 1.0
MOOC Sprachtechnologie in den Digital Humanities: Modul Korpuslinguistik
Meine Kollegen Simon Clematide, Martin Volk und ich starten diese Woche unseren Massive Open Online Course (MOOC) zu Sprachtechnologie in den Digital Humanities. Sie können sich ab sofort kostenlos ins Kurssystem einschreiben und dann über sechs Wochen in kleinen Häppchen einen Einblick in sprachtechnologische Aspekte der Aufbereitung und quantitativen Analyse von Textdaten und Korpora gewinnen.
Ich habe ein dreiteiliges Modul zu grundlegenden korpuslinguistischen Analysekategorien mit Hands-on-Teil, sowie zu visuellen Analysemethoden, vorbereitet. Die Videos dieses Moduls sind in meinem Online-Handbuch zur Korpuslinguistik auch außerhalb der MOOC-Plattform coursera publiziert. Für Angehörige von Schweizer Universitäten und Hochschulen sind die die Videos des ganzen Kurses auch über Switch Tube verfügbar.
Juliane Schröter und Robert Schikowski der Universität Zürich interviewten mich neulich in ihrem Podcast „angesprochen“ zum Thema „Suchen und Finden im Internet„. Ich bin alles andere als ein Spezialist beim Thema Suchmaschinen (Tipp: „Der Google-Komplex“ von Theo Röhle) und deshalb war das Interview ein guter Grund, mich ausführlicher mit Fragen zum Thema Googles Auswirkungen auf Gesellschaft und Wissenschaft auseinanderzusetzen. Aus korpuslinguistischer Perspektive sind solche Reflexionen natürlich ganz interessant – und hey, Code is Theory, deshalb ist es wichtig, die Funktionsweise von Suchmaschinen zu verstehen und deren Auswirkungen zu antizipieren! Juliane, Robert, danke für die interessanten Fragen!
Im Interview erwähnte oder benutzte Quellen/Sites:
![]()
Am 31C3 sprachen josch und ich (arche3000) über die Möglichkeiten und Folgend des digitalen Informationskrieges, wie man ihn bei der gegenwärtigen Ukraine-Krise gut beobachten kann. Dazu zeigten wir erste Ergebnisse unseres Bots, der für Informationskriege eingesetzt werden könnte – um zu antizipieren, was möglich ist und vielleicht auch bereits gemacht wird. Leider gruselig.
Die Videoaufzeichnung unseres Talks ist online:

Der 31C3 ist großartig – vielen Dank für die tolle Unterstützung, das Podium und überhaupt alles!
[Update vom 30. Dezember 2014, 18:00]
[Update vom 27. Januar 2015]
 Gestern endete das Symposium „Visuelle Linguistik„, das ich zusammen mit Marc Kupietz organisiert hatte. Aus unserer Sicht besonders interessant am Symposium war die breite Palette von unterschiedlichen Hintergründen, denen die Beiträge entstammten: Linguistik, Korpus- und Computerlinguistik, Digital Humanities, Informatik und Ästhetik – um nur die wichtigsten Perspektiven zu nennen.
Gestern endete das Symposium „Visuelle Linguistik„, das ich zusammen mit Marc Kupietz organisiert hatte. Aus unserer Sicht besonders interessant am Symposium war die breite Palette von unterschiedlichen Hintergründen, denen die Beiträge entstammten: Linguistik, Korpus- und Computerlinguistik, Digital Humanities, Informatik und Ästhetik – um nur die wichtigsten Perspektiven zu nennen.
Die Keynotes von Mark Lauersdorf, Martin Hilpert und Maximilian Schich boten den Rahmen für die 16 Vorträge und die zusätzlichen Poster und Live-Präsentationen. Am dritten Tag ermöglichte der Workshop von Sandra Hansen-Morath und Sascha Wolfer zu R, verschiedene Visualisierungsmethoden selber auszuprobieren.
Die Folien meines Eröffnungsvortrags, der „Visuelle Linguistik“ als lohnenswertes Forschungsfeld vorschlägt, sind ab sofort online verfügbar. In den kommenden Tagen werden auch die Folien weiterer Vorträge, sowie Berichte zur Tagung, auf www.visual-linguistics.net publiziert.
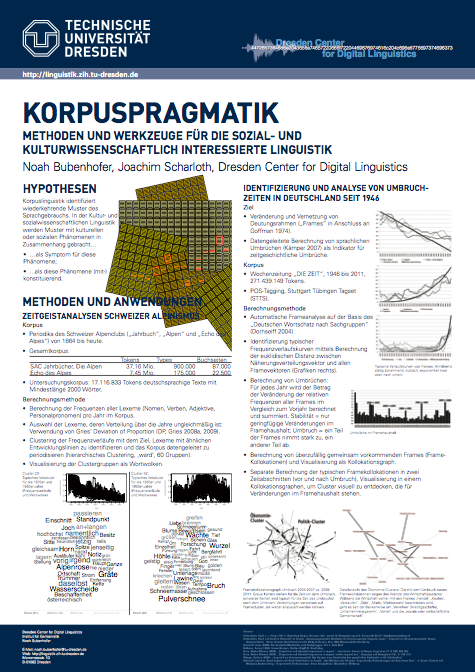 Die aktuelle ZEIT bringt auf Seite 27 einen großen Beitrag über Big Data in den Geisteswissenschaften. Grundlage sind Gespräche mit Joachim Scharloth und mir und eine Analyse von uns (und David Eugster): Wir untersuchten mit datengeleiteten Methoden das Archiv der gedruckten ZEIT in Nachkriegsdeutschland bis heute – die Studie ist hier im Preprint verfügbar* und dieses Poster (siehe Bild) enthält auf der rechten Seite eine Kürzestfassung davon.
Die aktuelle ZEIT bringt auf Seite 27 einen großen Beitrag über Big Data in den Geisteswissenschaften. Grundlage sind Gespräche mit Joachim Scharloth und mir und eine Analyse von uns (und David Eugster): Wir untersuchten mit datengeleiteten Methoden das Archiv der gedruckten ZEIT in Nachkriegsdeutschland bis heute – die Studie ist hier im Preprint verfügbar* und dieses Poster (siehe Bild) enthält auf der rechten Seite eine Kürzestfassung davon.

* Scharloth, Joachim/Eugster, David/Bubenhofer, Noah (2013): Das Wuchern der Rhizome. Linguistische Diskursanalyse und Data-driven Turn. In: Busse, Dietrich/Teubert, Wolfgang (Hrsg.): Linguistische Diskursanalyse. Neue Perspektiven. Wiesbaden: Springer VS. S. 345-380.
Soeben habe ich die erfreuliche Nachricht erhalten: Der Schweizer Nationalfonds fördert mein Projekt „Visual Linguistics: Grundlagen der Visualisierung von sprachlichen Daten“ über drei Jahre! Voraussichtlich ab 2015 werde ich das Projekt mit dem Ziel starten, ein „Visual Linguistics Framework“ zu erarbeiten. Es geht im Grunde um die Fragen:
Die äußerst positiven Gutachten ermutigen mich, die Aufgabe anzupacken! Danke an alle mir bekannten und unbekannten Unterstützer/innen des Projekts, die mir den nötigen Rückenwind geben!
Vor ein paar Tagen habe ich mein Facebook-Konto gelöscht. Es kostete mich nicht viel Überwindung, denn ich war kein aktiver Facebook-User. Trotzdem ist es interessant, sich zu überlegen, welche Gründe gegen die Facebook-Nutzung sprechen. Hier deshalb meine zehn Gründe – fotografisch untermalt –, die auch meine letzten Facebook-Posts waren.
Werbung in eigener Sache: Vom 19. bis 21. November 2014 findet in Hannover das Symposium „Visuelle Linguistik: Theorie und Anwendung von Visualisierungen in der Sprachwissenschaft“ statt, das ich zusammen mit Marc Kupietz (IDS Mannheim) organisiere. Gegenwärtig ist der Call for Papers offen: http://www.visual-linguistics.net/symposium/
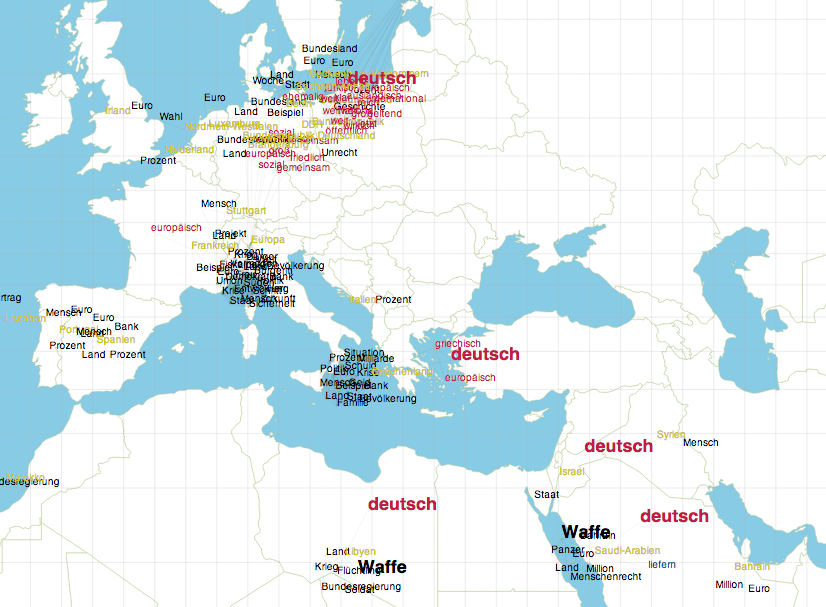
Geokollokationen, Deutscher Bundestag, Partei Die Linke WP 17, vgl. bubenhofer.com/geocollocations/
Wir freuen uns nicht nur über Beiträge, die Methoden der Visualisierung praktisch erproben, sondern auch über solche, die diese Methoden theoretisch reflektieren. Ganz explizit richtet sich das Symposium nicht nur an Wissenschaftler/innen aus der Korpus- oder Computerlinguistik, sondern aus der gesamten Sprachwissenschaft, den Digital Humanities und angrenzenden Disziplinen.
Visualisierungen zur Präsentation von Forschungsergebnissen, besonders aber auch zur Exploration von Daten, haben eine lange Tradition in der Linguistik. Man denke z.B. an Dialektkarten oder Syntaxbäume. Aber auch Transkripte gesprochener Sprache sind eine Form von Visualisierung. Besonders wichtig sind heute Visualisierungen natürlich in der quantitativen Korpuslinguistik, wo es ohne fast nicht mehr geht.
Mein Online-Handbuch Korpuslinguistik („Einführung in die Korpuslinguistik„) enthält ein Kapitel zur Erstellung von eigenen Korpora. Es ist dabei das Ziel, einfache Wege zu beschreiben, wie man aus unterschiedlichen Quellen ein Korpus bauen kann – Wege, die auch für technisch weniger erfahrene Linguistinnen und Linguisten gangbar sind.
Entscheidend für die möglichen Wege sind dabei zwei Dinge:
Viele Konkordanzprogramme wie z.B. das recht verbreitete AntConc (mein Tutorial hier) lesen unstrukturierte Textdateien, allenfalls auch HTML, allerdings ohne die HTML-Tags zu beachten. Es ist damit unmöglich, Metadaten mit den Dokumenten zu assoziieren.
State-of-the-Art ist aber natürlich XML. Die Open Corpus Workbench, TXM (Unicode-XML-TEI text/corpus analysis platform) oder Weblicht lesen beispielsweise XML-Daten und können so codierte Metadaten und Auszeichnungen im Text (Titel, Absätze, Sätze etc.) auslesen.
Wenn es jedoch darum geht, einfache Wege aufzuzeigen, wie man z.B. von heruntergeladenen Webseiten zu sauber codierten XML-Dokumenten kommt, wird es schwierig. Ein nahe liegender Weg, den ich z. B. in meinem Aufsatz „Skandalisierung korpuslinguistisch: Eine empirisch-linguistischer Blick auf die Berichterstattung zur ‚Wulff-Affäre‘“ (Linguistik Online 61, 4/2013) beschreibe, geht so (für Unix-Systeme, Mac):
Dieser Weg funktioniert besonders dann gut, wenn man eine Serie von gleich strukturierten Webseiten herunterladen möchte, z.B. Web-Foren, Online-Zeitungen etc. Etwas flexibler (und in den Funktionen mächtiger) ist z.B. der Web-Crawler Heritrix, der jedoch auch nochmals schwieriger zu bedienen ist.
Doch was ist der gangbare Weg für Linguistinnen und Linguisten, die keine Lust haben, sich in die Tiefen der XML-Verarbeitung mit XSLT, XPath etc. zu begeben? Eine mögliche Alternative, an der ich arbeite, ist:
Es handelt sich also noch um eine offene Baustelle und Anregungen dazu sind sehr willkommen! Diese Seite aus meinem Online-Handbuch zur Korpuslinguistik führt wenigstens schon mal (hoffentlich auch für Laien verständlich) in XML für die Korpuslinguistik ein.
Update vom 23. Januar 2014: Inzwischen habe ich einen Weg von HTML zu XML in meinem Online-Handbuch beschrieben. Um XSLT kommt man nicht herum, aber ich hoffe, es verständlich beschrieben zu haben. Zudem habe ich dargestellt, wie man mit geschickter Anwendung von Regulären Ausdrücken von einer strukturierten Text-Datei zu XML kommt.