
Was meinen wir eigentlich, wenn wir von „Terrorismus“ sprechen? 9/11? Der „Deutsche Herbst“ von 1977? Oder München 1972? Die Bedeutung von „Terrorismus“ ist breit und vor allem an bestimmte Diskurse gebunden. 1972 versteht man etwas anderes unter Terrorismus als heute.
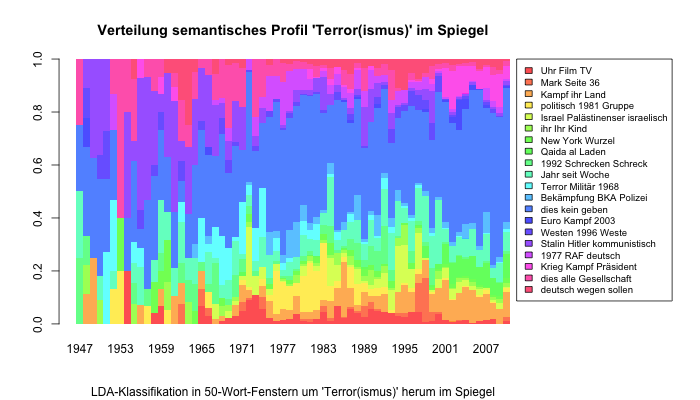
Inspiriert von einem Beitrag von Rohrdantz et al. (2012) wollte ich ausprobieren, ob die Veränderung der Bedeutung eines Wortes über ein Verfahren der automatischen Textklassifikation (LDA, Latent Dirichlet Allocation) anhand des Spiegel-Korpus beantwortet werden kann. Das hier kam dabei raus:
Was ich genau gemacht habe, erkläre ich im Folgenden.
LDA (entwickelt von Blei/Ng/Jordan) ist eine Methode, um das Thema von Dokumenten maschinell zu bestimmen (Topic Modelling) und basiert in der von Rohrdantz et al. vorgelegten Arbeit auf der Analyse des vorkommenden Vokabulars. Natürlich kann man nicht nur ganze Dokumente so thematisch klassifizieren, sondern kann die Methode auch anwenden, um unterschiedliche Bedeutungsnuancen eines Wortes in seinem Kontext zu unterscheiden und ggf. auch die Entwicklung dieser Bedeutungsnuancen über die Zeit zu untersuchen. Dahinter steckt die Idee, dass sich unterschiedliche Bedeutungsnuancen durch eine bestimmte Einbettung des Wortes auszeichnen. Finde ich die unterschiedlichen Einbettungen, kenne ich damit auch die Bedeutungsnuancen.
Da es sich um ein unüberwachtes Lernverfahren handelt, muss vorher nur festgelegt werden, wie viele unterschiedliche Themen bzw. Bedeutungsnuancen gefunden werden sollen. Das Modell liefert dann nicht nur die Klassifikation der Texte/Belege, sondern charakterisiert die Klassen anhand des typischsten Vokabulars.
Ich habe nun für eine Reihe von Lexemen Belege aus einem Spiegelkorpus, das alle Texte des gedruckten Spiegels von 1947 bis 2010 enthält, extrahiert. Die Belege umfassen jeweils 25 Wörter vor und nach dem Suchwort. Für die Lemmata „Terror“ und „Terrorismus“ handelt es sich um 12.250 Belegstellen. Ich exportierte die Belege jeweils mit Publikationsdatum und den Grundformen anstelle der flektierten Wortformen aus dem Korpus, um die Komplexität für die anschließende Modellierung zu reduzieren.
Nun kann man auf den Daten ein LDA-Modell trainieren. Ich verwendete dafür MALLET, für dessen Bedienung es bei den Programming Historians eine gute Anleitung gibt. Der Algorithmus spuckt nun für die Belege von „Terror(ismus)“ folgende Klassen aus:
- Uhr Film TV Thema Carlos ZDF ARD Carlo 1 deutsch
- Mark Seite 36 _( 10 Verlag 11 GrafiktextEnde 12
- Kampf ihr Land neu international Staat Regierung
- politisch 1981 Gruppe Terrorismus italienisch
- Israel Palästinenser israelisch palästinensisch
- ihr Ihr Kind Frau Leben Mann jung Familie mein
- New York Wurzel Stadt Wurzeln Luft Bild klein
- Qaida al Laden Pakistan 2003 Bin 2002 Lade Anschlag
- 1992 Schrecken Schreck Mord Land Kosovo 1991 weiß
- Jahr seit Woche Mensch letzt vergangen drei Million
- Terror Militär 1968 ihr doch türkisch Türkei
- Bekämpfung BKA Polizei 2007 Kriminalität Schily
- dies kein geben müssen alle wollen doch dass sagen
- Euro Kampf 2003 4 5 Peter 3 9 Islam 6 Propyläen
- Westen 1996 Weste ins 1993 einst ziehen Stimme 1997
- Stalin Hitler kommunistisch Partei sowjetisch Macht
- 1977 RAF deutsch SPD Hans Gespräch CDU 1978 Klein
- Krieg Kampf Präsident Bush US Irak USA 2002 Amerika
- dies alle Gesellschaft politisch Mittel neu Mitteln
- deutsch wegen sollen Gericht neu Mann Geheimdienst
Natürlich kann man nun in die Belege rein und sehen, welchen Belegen welche Klasse zugewiesen wurde. Ich wollte nun aber sehen, wie sich diese Klassen auf den ganzen Zeitraum verteilen. Die Grafik ganz oben stellt dies in der Übersicht dar.
Man sieht, dass der größte Bereich die Klasse 13 ist (dies kein geben müssen alle wollen doch dass sagen), die wenig aussagekräftig ist und auch mehr oder weniger stabil über den ganzen Zeitraum verteilt ist. Es gibt aber andere Klassen, die unregelmäßig verteilt sind. Im Detail:
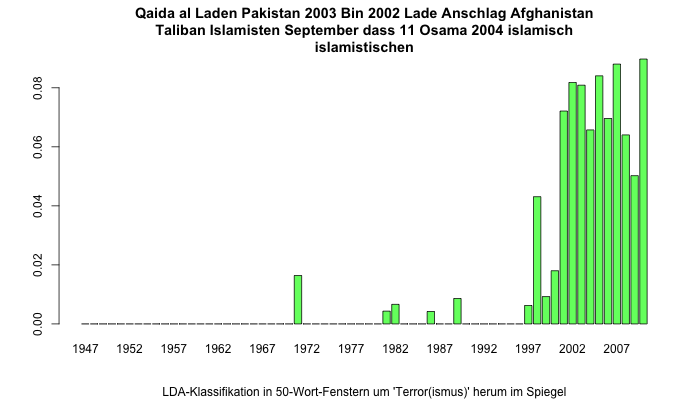
Dieses Bild zeigt die Anteile von Belegen der semantischen Klasse, die mit „Qaida, al, Laden, Pakistan, 2003“ etc. am besten beschrieben werden kann. Hier sehen wir den Kaida-Terror seit 9/11, wobei es bereits vorher Belege gibt, die dieser Lesart von „Terror“ ähneln, da Osama bin Laden natürlich auch vorher bereits Thema war.
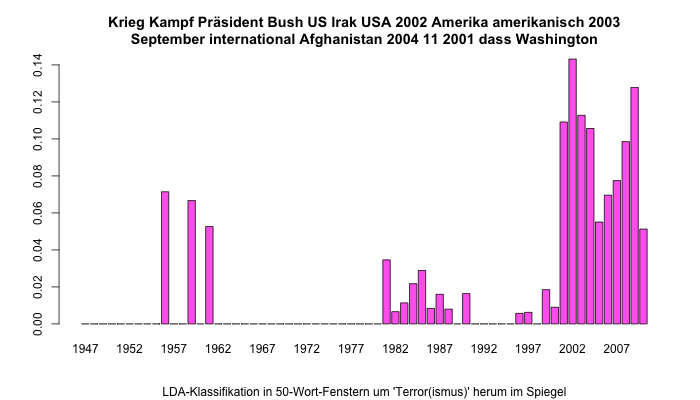
Eine ähnliche Lesart zeigt diese Grafik, wobei hier der Fokus auf dem Irakkrieg liegt, in dessen Kontext „Terror“ eine leicht andere Lesart entwickelt.
Terror ist jedoch seit den 1970er-Jahren ein ständiges Thema der Sicherheitsorgane Deutschlands, wie das folgende Schaubild zeigt.
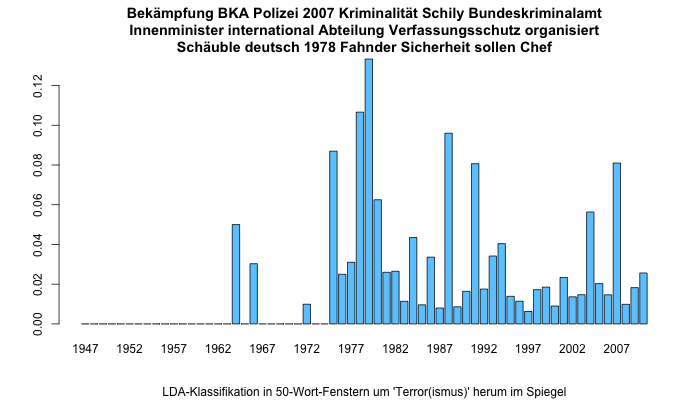
Bei diesem Aspekt von „Terror“ stehen die polizeilichen, kriminalistischen Bekämpfungsmethoden im Vordergrund, wobei diese nach 9/11 erstmal nicht im Vordergrund standen, da dann Terrorbekämpfung als Krieg aufgefasst wurde.
Der Grund für die Terrorbekämpfung in den 70er-Jahren liegt natürlich im „Deutschen Herbst“ begründet, der sich im folgenden Schaubild abzeichnet:
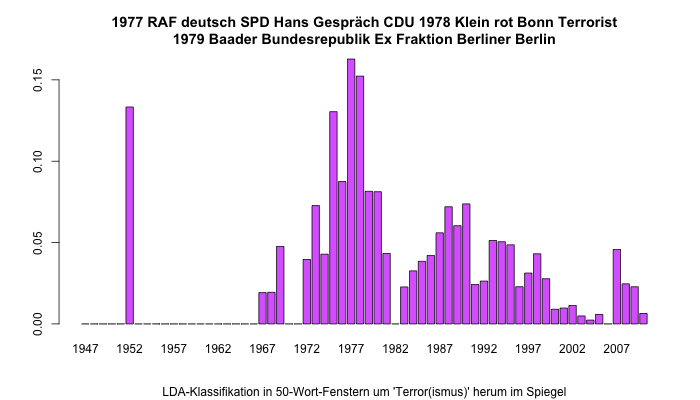
Das gleiche Schaubild oben zeigt dann in den 80er und 90er weitere Ausschläge, was auf die Morde und Anschläge der RAF bis zur Auflösung 1998 zurückzuführen ist. Die letzte Spitze ab 2007 steht wahrscheinlich im Kontext mit den Entlassungen von RAF-Mitgliedern aus der Haft.
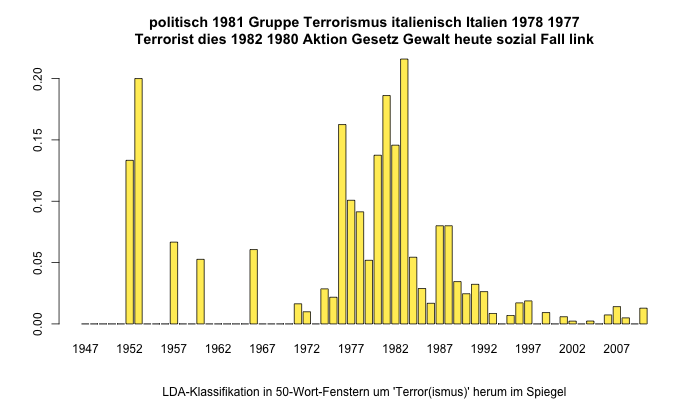
Was für Deutschland der „Deutsche Herbst“, sind für Italien die „Brigate Rosse“ des italienischen Linksterrorismus:
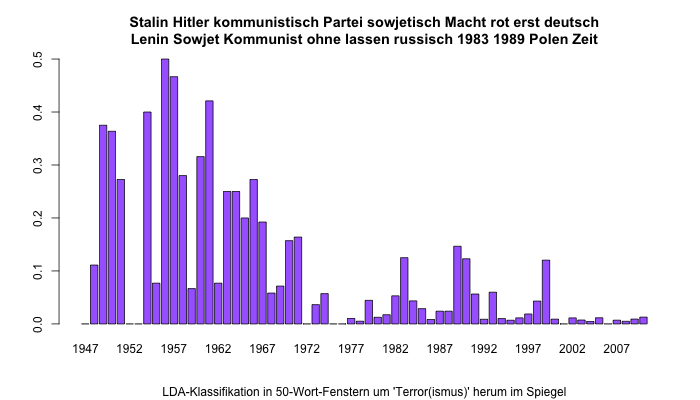
Typisch für die älteren Daten ist eine Verwendung von Terror im Kontext der Diktatoren Stalin und Hitler und der Sowjetunion:
Letztlich zeichnet sich noch der Palästinenserkonflikt in den Daten ab:
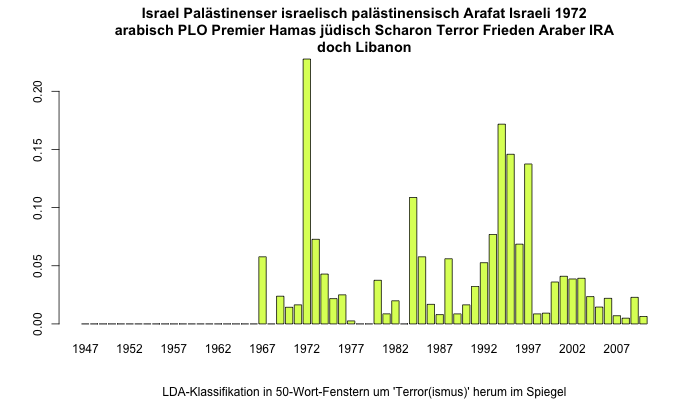
Der erste Höhepunkt in den 1970er-Jahren könnte auf die Folgen des Sechstagekriegs, den Jordanischen Bürgerkrieg und dann insbesondere den Terroranschlag am 30. Mai 1972 am internationalen Flughafen von Tel Aviv verweisen. Der Höhepunkt um 1994/95 geht wahrscheinlich auf die Terroranschläge der Hamas in Israel zurück (1993 verübte die Hamas den ersten Anschlag in Israel).
Die dargestellten Klassen scheinen plausibel und das Verfahren konnte wichtige Terrordiskurse aufdecken. Einige Klassen sind jedoch etwas undurchsichtig und müssen noch genauer geprüft werden. Zudem hat die Anzahl der angestrebten Klassen natürlich einen großen Einfluss auf die Klassifizierung.